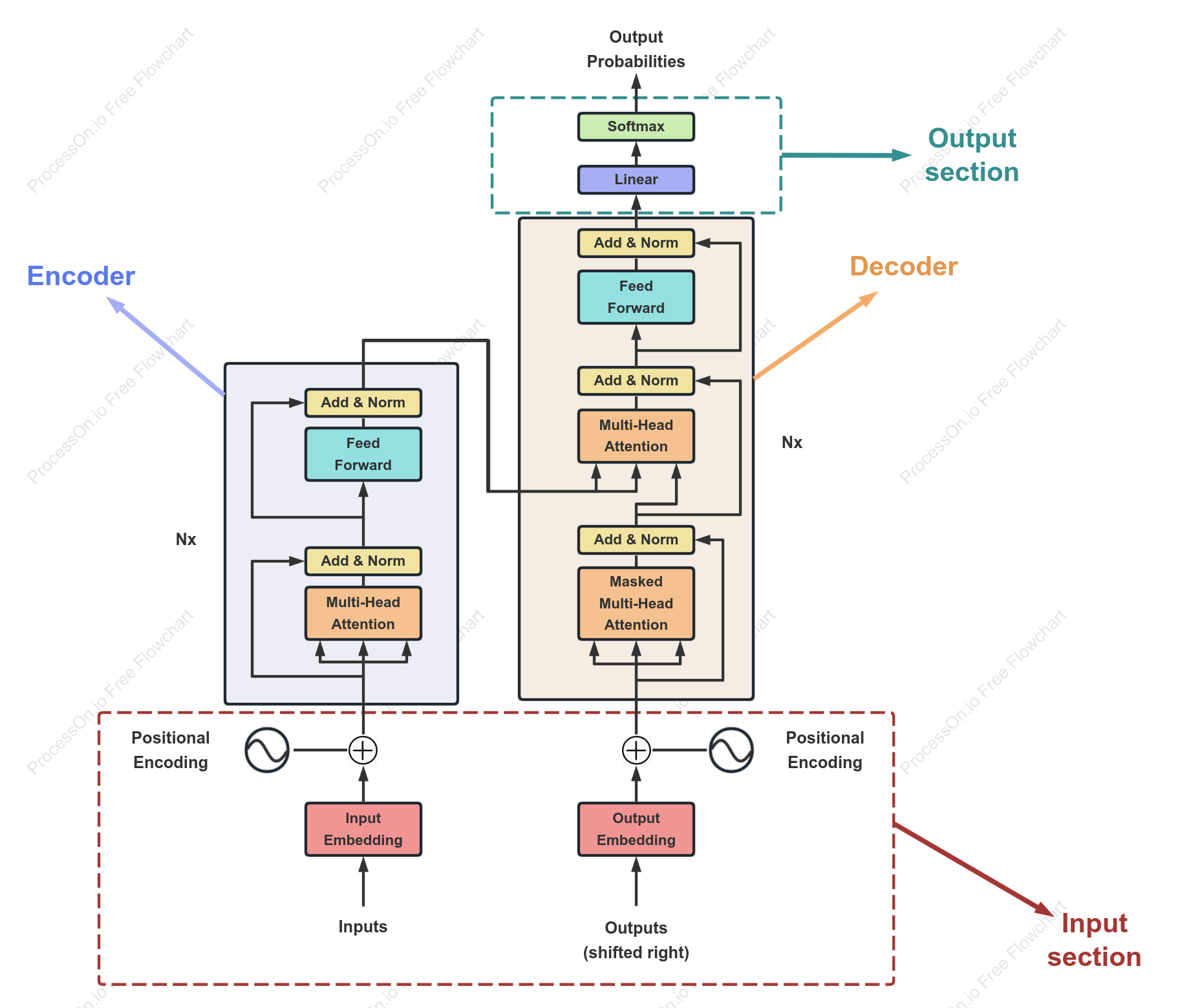

Transformer model architecture
2 Report
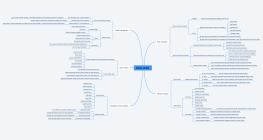
This template is suitable for drawing neural network structure diagrams of Transformer models, focusing on the core components of the encoder and decoder and their data flow relationships. It clearly presents modules such as Input Embedding, Positional Encoding, Multi-Head Self-Attention, Feed-Forward Network, Layer Normalization, and Residual Connections. It is suitable for use as illustrations in papers, technical sharing presentations, model explanation tutorials, or algorithm reproduction documents, helping readers intuitively understand the Transformer's workflow and information transmission paths.
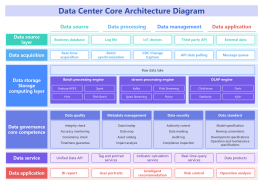
Related Recommendations
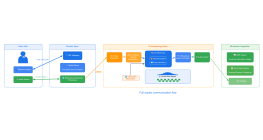
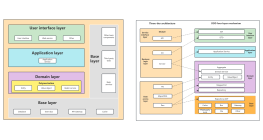
Other works by the author
Outline/Content
See more
Add & Norm
PositionalEncoding
Input section
Nx
Linear
FeedForward
Encoder
Output section
OutputProbabilities
MaskedMulti-HeadAttention
Multi-HeadAttention
OutputEmbedding
Outputs(shifted right)
InputEmbedding
Softmax
Inputs
Decoder
Collect
Collect
Collect

Collect

0 Comments
Next Page