
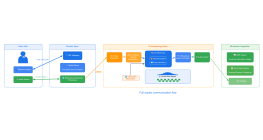
AI large language model RAG retrieval enhancement generation flow chart
9 Report
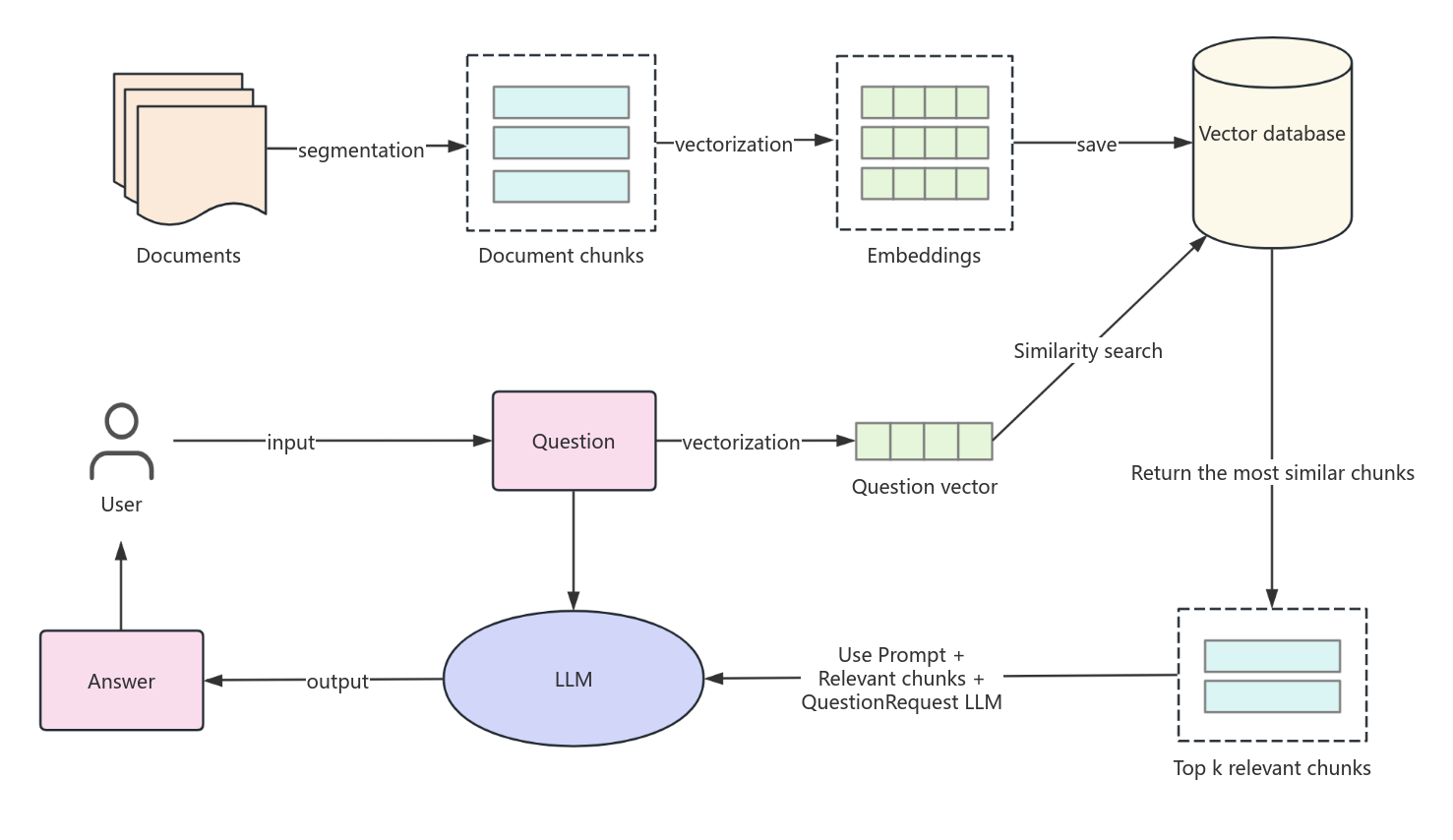
This flowchart illustrates the process of enhancing retrieval in AI large language models using RAG (Retrieval-Augmented Generation) techniques. It outlines the journey from user input to generating answers, emphasizing key steps such as vectorization, similarity search, and document chunk segmentation. The process begins with vectorizing the input question and conducting a similarity search in a vector database to identify the top relevant document chunks. These chunks, combined with the user’s question, form a prompt for the language model, ultimately generating a precise answer. This structured approach ensures efficient and accurate information retrieval.
Related Recommendations
Other works by the author
Outline/Content
See more
Vector database
Documents
save
output
Use Prompt +Relevant chunks +QuestionRequest LLM
Answer
Similarity search
Question vector
vectorization
input
LLM
Embeddings
User
Document chunks
segmentation
Return the most similar chunks
Question
Top k relevant chunks
Collect


Collect

0 Comments
Next Page