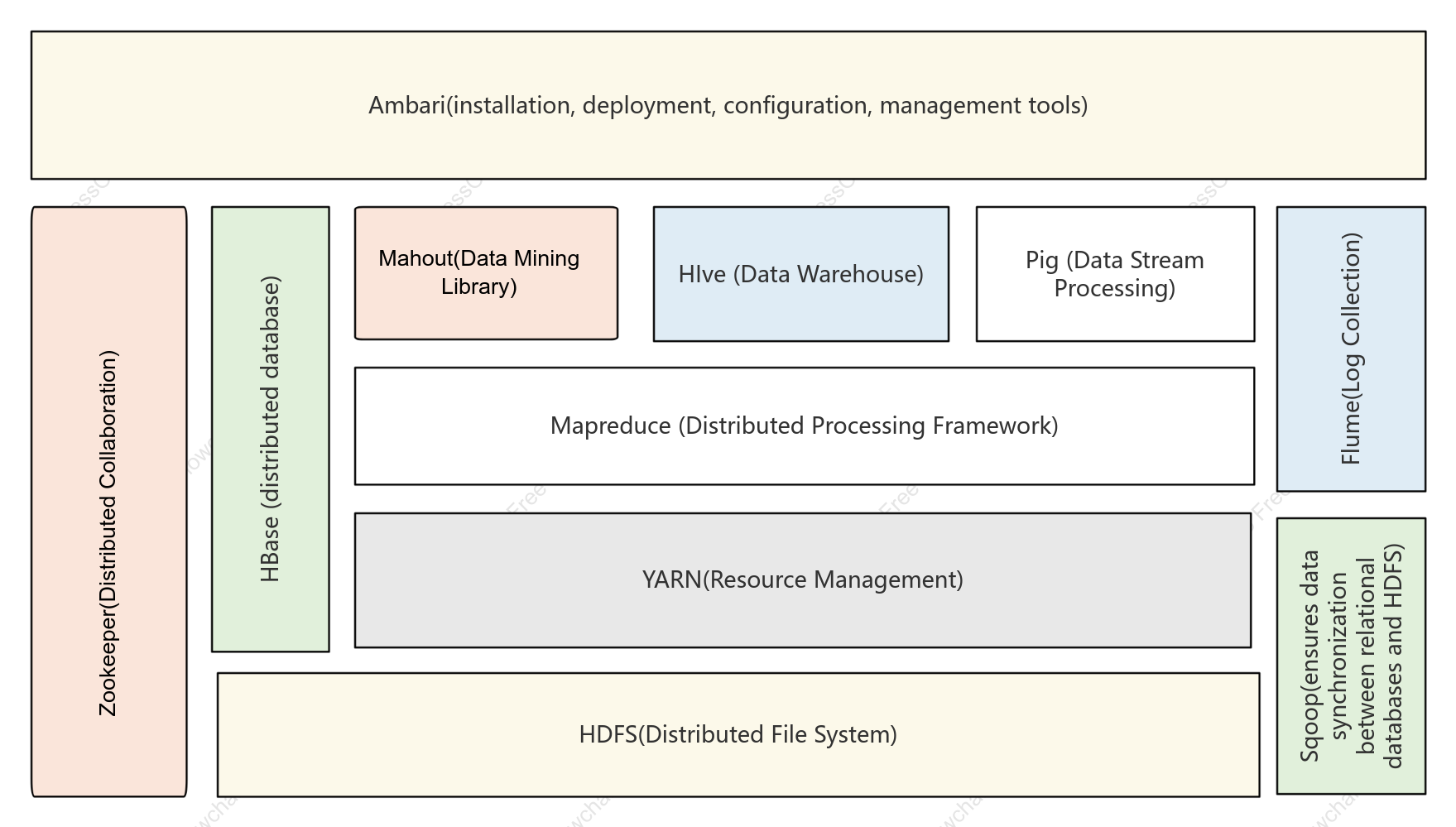

Hadoop system architecture
0 Report
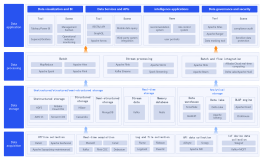
The Hadoop system architecture is a cornerstone design in the field of big data processing, aiming to achieve highly reliable and fault-tolerant processing of massive amounts of data on general-purpose hardware clusters through a distributed storage and computing framework. This section systematically describes the core layered structure of Hadoop, including three core components: the HDFS distributed file system, the YARN resource scheduler, and the MapReduce distributed computing model. HDFS adopts a master-slave architecture, with the NameNode managing metadata and namespaces, and DataNodes responsible for storing actual data blocks and ensuring redundancy to guarantee high data availability. YARN, as a resource management and task scheduling platform, encompasses ResourceManager, NodeManager, and ApplicationMaster, decoupling computing resources from job lifecycles. MapReduce defines a parallel computing paradigm for data sharding, Shuffle sorting, and Reduce aggregation. By analyzing the interaction protocols, heartbeat mechanisms, and fault recovery strategies between each module, this architecture lays a systematic theoretical foundation for understanding the horizontal scalability and data locality optimization logic of distributed systems.
Related Recommendations
Other works by the author
Outline/Content
See more
Sqoop(ensures data synchronization between relational databases and HDFS)
HDFS(Distributed File System)
HBase (distributed database)
Flume(Log Collection)
HIve (Data Warehouse)
Pig (Data Stream Processing)
YARN(Resource Management)
Zookeeper(Distributed Collaboration)
Mapreduce (Distributed Processing Framework)
Mahout(Data Mining Library)
Collect
Collect
Collect
Collect


0 Comments
Next Page