系統的レビューやメタアナリシスを実施する際、ほぼすべての主要な学術誌では、論文に図(PRISMAフローチャート)を含めることを著者に求めています。これはPRISMA(系統的レビューおよびメタアナリシスのための推奨報告項目)声明の中核となるツールであり、査読者がレビューの質を判断する際に最初に用いる基準です。
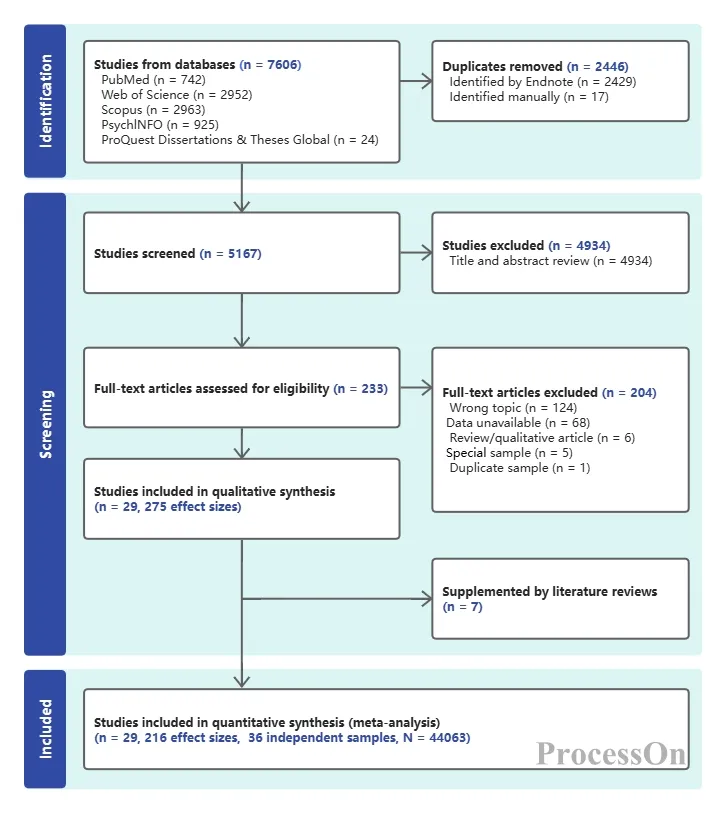
科学研究に不慣れな大学院生や医学生の多くは、PRISMAフローチャートを作成する際に戸惑うことが多い。フローチャートの各ボックスには何を書くべきか?数値はどのように計算すべきか?除外記録はどの程度詳細に記述すべきか?苦労して作成した図が、なぜ査読者から「データループが不完全」だと批判されるのか?
もしあなたもこれらの問題に悩んでいるなら、心配しないでください。今日は、PRISMAフローチャートとは何か、その価値、基本的な枠組み、そしてフローチャートツールを使った描き方について、詳しく解説します。
PRISMAフローチャートは、2009年にMoherらによって初めて提案され、2020年と2025年に2回の主要な改訂が行われました。完全なメタ分析には「結果」だけでなく「プロセス」も必要であるのと同様に、PRISMAフローチャートの重要性は、標準化されたチャートを使用して、研究者が「干し草の山から針を探す」ところから「結果をスクリーニングする」ところまでのすべてのステップを記録し、レビューがどのように書かれたか、文献がどのようにスクリーニングされたか、各ステップで何件の記事が除外されたか、そして除外の理由を、最も直感的な方法でジャーナルや同僚に伝えることにあります。
PRISMAフローチャートは厳密に標準化された構造に従っており、4つの主要な構成要素から成ります。
識別段階:文献がどのデータベースまたは情報源から見つかったか、見つかった記事の数、および重複した記事の数を示します。
スクリーニング段階:重複排除後に保持された記事数と、タイトルおよび要約に基づいて除外された記事数を示します。
適格性評価:全文読解段階に入った後、何件の記事が採用され、何件が除外され、除外の具体的な理由は何か?
選定段階:この段階では、最終分析および結果集計に含める論文数を確定します。
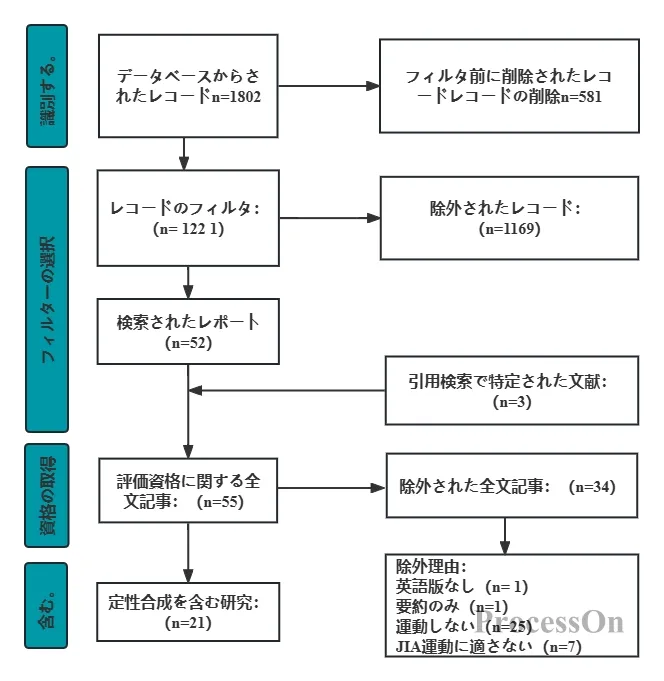
これら4つの段階は相互に接続されており、完全な「デジタル閉ループ」を形成するためには、各リンクの数が完全に一致している必要がある。
PRISMAフローチャートの描き方を理解する前に、まずその価値を理解しましょう。多くのジャーナル査読者は、フローチャートのないシステマティックレビューやメタアナリシスを却下します。これはジャーナルが意図的に難しくしているのではなく、PRISMAフローチャートが実際に以下の主要な機能を果たしているからです。
透明性と信頼性の向上:PRISMAフローチャートは研究選定プロセスを詳細に示しており、読者は各段階で選定された論文数と除外理由を明確に確認できます。ジャーナル編集者と査読者は、このフローチャートを用いて研究選定プロセスの厳密性と網羅性を評価し、レビューの信頼性や重要な文献が漏れていないかを判断することができます。
再現性の確保:フローチャートには各段階の操作手順が完全に記録されているため、他の研究者は同じスクリーニングロジックに基づいてこの研究を再現し、その結論を検証し、最終的には科学的再現性における革命を推進することができます。
バイアスと潜在的なエラーの低減:フローチャートは、本文全体における学術的不正行為、欠陥のある研究デザイン、不完全なデータなど、各除外ステップの理由を明確に示しています。この透明性により、読者はレビューに選択的報告バイアスがあるかどうかを判断し、最終的な研究結果の客観性を評価することができます。
厳格な出版要件への対応:多くの学術誌や研究資金提供機関は、すべてのシステマティックレビューおよびメタアナリシスがPRISMAガイドラインに準拠することを明示的に要求しています。PRISMA準拠の文書が添付されていない原稿は、多くの場合、最初の編集審査段階で却下されます。
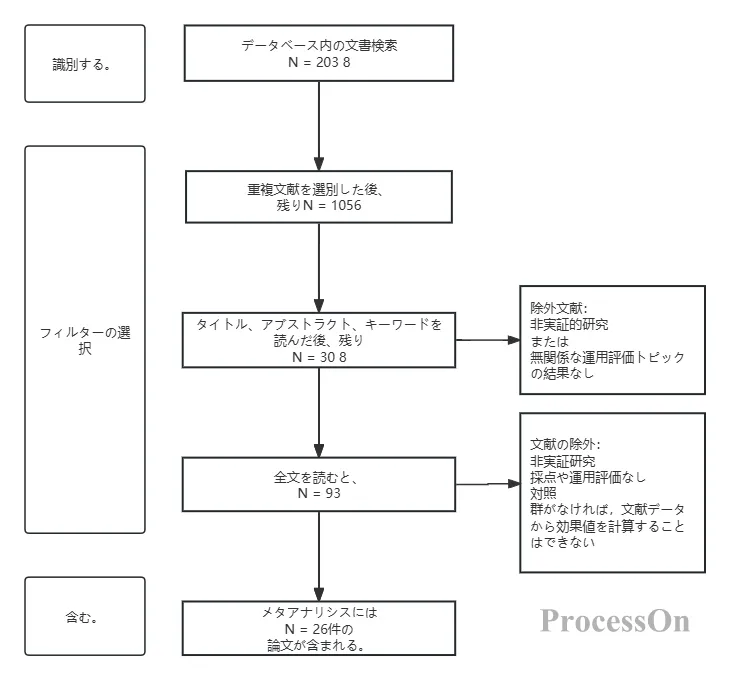
標準的なPRISMAフローチャートは、通常、縦長の多階層ボックス図に似ており、上から下へ、識別、スクリーニング、適格性評価、組み入れという4つの主要な段階を経て進行します。次のセクションでは、各段階の具体的な意味を詳しく説明します。
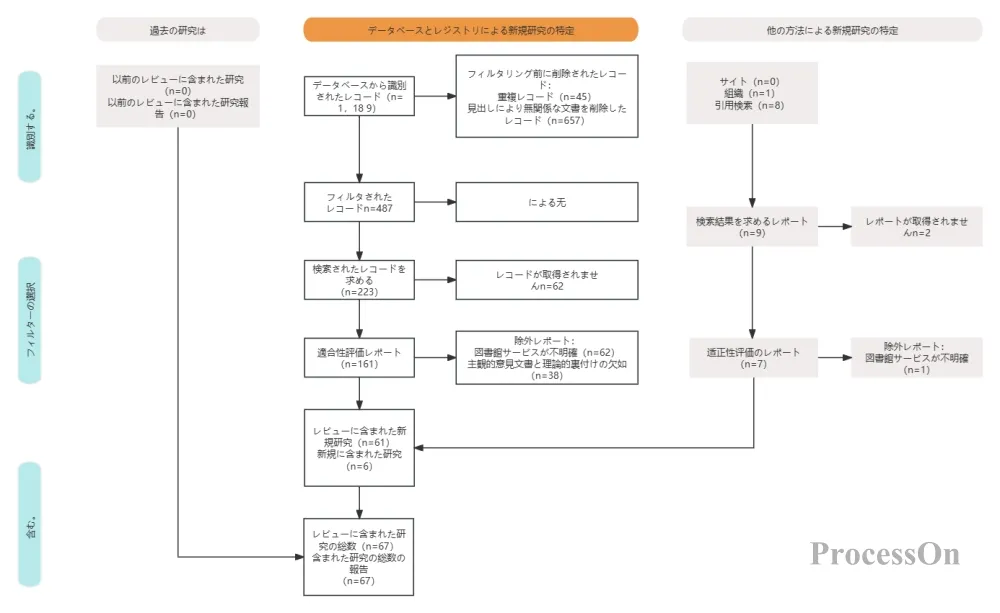
この段階では、「文献はどこで見つけたのか?全部でいくつの記事を見つけたのか?」という疑問に答えます。
フローチャートの上部には通常、「データベース検索で得られた記録」と「その他の情報源から得られた記録」というラベルの付いた複数の四角形があります。研究者は、PubMed、Web of Science、Embase、Cochrane Libraryなど、検索したデータベースを詳細にリストアップし、各データベースの検索結果数を括弧内に示さなければなりません。
次に、2つのチャネルは「重複削除」ステップで合流します。同じ論文が複数のデータベースに索引付けされている可能性があるため、EndNoteやNoteExpressなどの文献管理ソフトウェアを使用して自動的に重複を削除し、グラフに残った文献の総数を明確に表示することが不可欠です。ここで、文献数は正確でなければなりません。たとえば、PubMedで1200件、Web of Scienceで1100件を含む合計3000件の論文が見つかった場合、これらを明確に記録する必要があります。これは文献検索の網羅性を示し、査読者にあなたの綿密さを伝えることになります。
この段階は「初期スクリーニング」とも呼ばれ、「重複を除去した記事のうち、本当に関連性のある記事はいくつあるのか?」という問いに答えるものです。
研究者は、タイトルと抄録の情報に基づいて迅速なフィルタリングを行う必要があります。このステップの目的は、明らかに無関係な文献を除外することです。例えば、「高血圧治療薬」の臨床試験を実施したいのに、動物実験モデルに関する文献や、研究対象が全く異なる文献が見つかった場合などです。タイトルと抄録によるフィルタリング後、残った論文は次の段階である全文レビューに進みます。
この段階の数値も誤りやすい。重複文書の総数から却下されたタイトルと抄録の数を差し引いた数が、全文レビューに進む文書の数と等しくなければならない。加算と減算が一致しない場合、フローチャートは役に立たなくなる。専門家は、研究者に対し、スクリーニング中に記録を取り、最後に却下された文書の数を思い出そうとしないことを勧めている。
適格性評価(「全文レビュー」とも呼ばれる)は、フローチャート作成において最も学術的に厳密なステップです。研究者は、残りの文献の全文をダウンロードし、注意深く読み、事前に設定された包含基準と除外基準に従って、論文ごとに分析する必要があります。例えば、システマティックレビューの包含基準は、「ランダム化比較試験」、「サンプルサイズが50例以上」、「完全なアウトカム指標」などとなる可能性があります。
この段階では、包含基準を満たさない文献はすべて明確にマークし、分類する必要があります。一般的な理由としては、「研究デザインが不適合」、「対象集団が不適合」、「介入が不適合」、「アウトカム指標が欠落」などが挙げられます。レビュー担当者はこのセクションを用いて、レビューの除外基準が妥当かどうか、また除外すべきではなかった重要な文献が除外されていないかどうかを判断します。
フローチャートの最終的な目的は、複数回のスクリーニングを経て、最終的に定性的統合(システマティックレビュー)または定量的統合(メタアナリシス)に採用される論文数を示すことです。フローチャートには、最終的に採用された論文の総数を示すだけでなく、「最終的に採用された論文数はxx件です」という脚注が添えられることがよくあります。統合された効果量を用いたメタアナリシスの場合は、抽出された効果量の数も示す必要があります。
以下は、準備から実際の製図までの完全な操作ガイドです。
文献調査を実施する:複数のデータベースを用いて関連文献を検索し、検索戦略と結果(取得した文書の総数を含む)を記録する。単に合計数を記録するだけでなく、これらの数値を個別にリストアップすることで、後続のフローチャートの完全性と議論の妥当性を確保する。
重複を削除した数を正確に計算します。EndNoteなどの文献管理ソフトウェアにすべての参考文献をインポートし、自動重複排除を実行します。公式テンプレートでは、これら2つのソースを別々にラベル付けする必要があるため、「自動重複排除によって削除された参考文献の数」と「手動重複排除によって削除された参考文献の数」を記録します。
除外理由を詳細に記録し、コードで分類してください。スクリーニングまたは全文レビューの段階で除外された文献については、「研究デザインに一貫性がない」「介入方法に一貫性がない」などの理由を紙または電子データで記録し、標準形式で保存してください。こうすることで、最後に要約する際に、統計情報を直接集計したり、グラフを作成したりすることができます。
PRISMAフローチャートを作成する:選択結果に基づいて、ProcessOnなどのツールを使用してPRISMAフローチャートを作成します。テンプレートコミュニティで「PRISMAフローチャート」を検索し、テンプレートを直接適用した後、テキストや数値を手動で入力して修正することもできます。
エクスポート機能は、PNG、JPG、SVG、PDFなど、複数の画像フォーマットに対応しており、ドキュメントに直接埋め込むことができます。チームでの共同作業が必要な場合は、チームメンバーを直接招待してフローチャートを共同作成したり、コミュニケーションやコメントを交わしたり、リアルタイムで更新したりすることも可能です。
検証作業
フローチャートが完成したら、厳密なデータ検証が不可欠です。科学編集における簡単な経験則は次のとおりです。最上部の取得済み文書総数から最下部の分析対象文書総数まで、この経路上のすべての減算は、結果の総数と等しくなければなりません。たとえば、「取得済み文書総数」から「重複排除後の数」を引いた数から「タイトル/抄録で除外した数」を引いた数から「全文で除外した数」を引いた数が、最終的な「対象研究数」と等しくなければなりません。
非常に簡単な自己チェック手順は次のとおりです。PRISMAフローチャートの最初のドラフトを受け取ったら、まず左上隅の「ロック済み」(各データベースの合計)の合計が「レコードの総数」と等しいかどうかを確認します。次に、最初の重複排除スクリーニングの差異ロジックを検証します。その後、テキスト全体を除外した理由を要約して提示します。最後に、上部の元の合計から除外されたすべての数を引いた数が、下部の「最終的な包含」数と完全に一致するかどうかを確認する必要があります。
PRISMAフローチャートの完成度は、ある程度、システマティックレビューの方法論的な厳密さを直接反映します。メタアナリシスやシステマティックレビューの提出を準備しているチームにとって、必要だからといってPowerPointでフローチャートを手作業で作成するのは避けるべきです。ProcessOnは、高品質なPRISMAフローチャートを簡単に作成できるだけでなく、データ視覚化機能やバージョン履歴追跡機能も提供しており、共同作業による修正を容易にし、変更履歴のトレーサビリティを確保します。