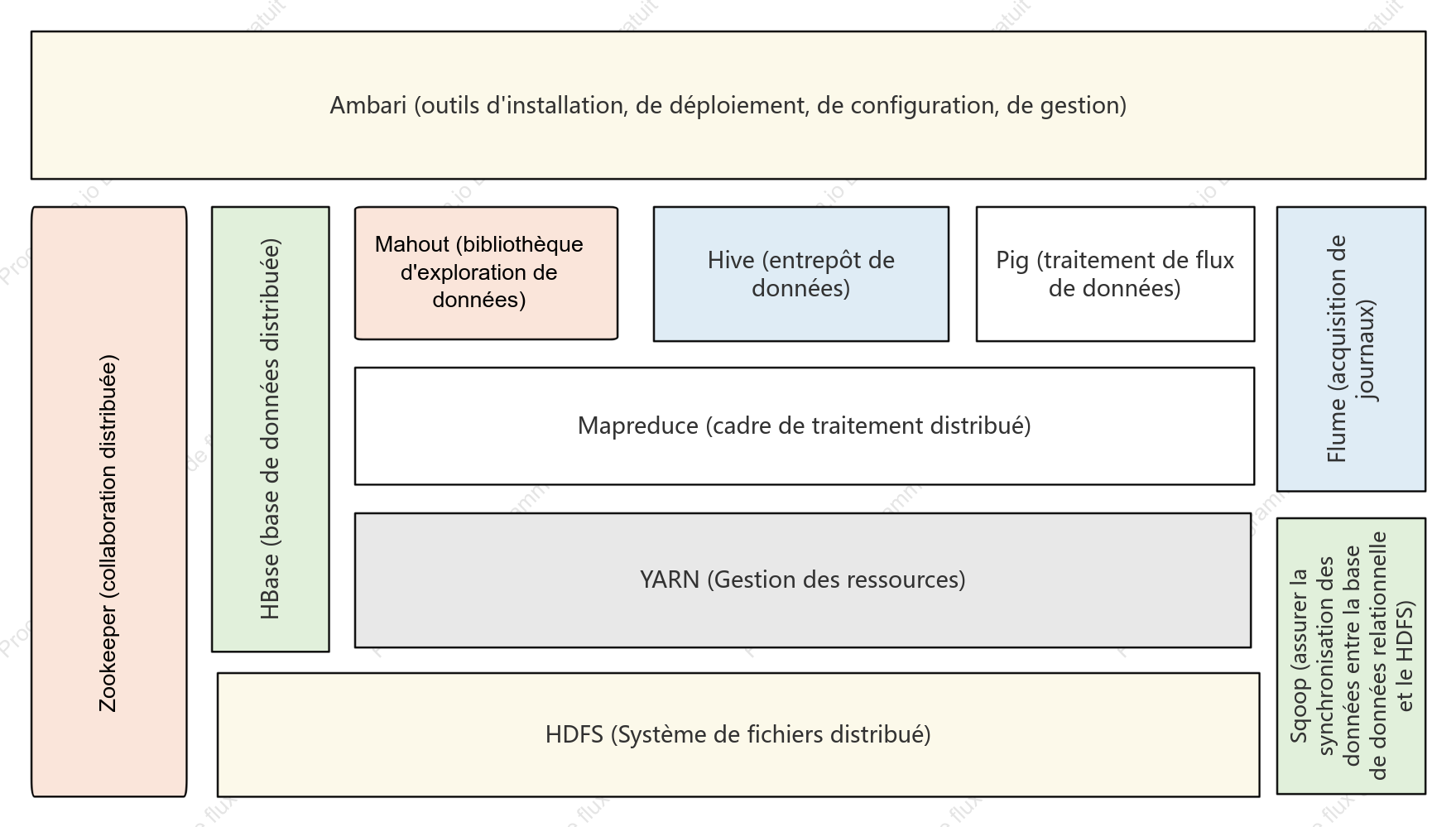

Architecture du système Hadoop
0 Rapport
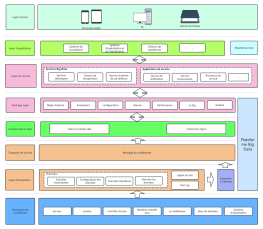
L'architecture système Hadoop est un pilier du traitement des données massives (Big Data), visant à garantir un traitement hautement fiable et tolérant aux pannes de volumes massifs de données sur des clusters matériels à usage général, grâce à un cadre de stockage et de calcul distribué. Cette section décrit en détail la structure en couches de Hadoop, comprenant trois composants essentiels : le système de fichiers distribué HDFS, le planificateur de ressources YARN et le modèle de calcul distribué MapReduce. HDFS adopte une architecture maître-esclave : le NameNode gère les métadonnées et les espaces de noms, tandis que les DataNodes stockent les blocs de données et assurent la redondance pour garantir une haute disponibilité des données. YARN, plateforme de gestion des ressources et de planification des tâches, comprend ResourceManager, NodeManager et ApplicationMaster, découplant ainsi les ressources de calcul du cycle de vie des tâches. MapReduce définit un paradigme de calcul parallèle pour le partitionnement des données, le tri par mélange (Shuffle) et l'agrégation par réduction (Reduce). En analysant les protocoles d'interaction, les mécanismes de pulsation et les stratégies de récupération des pannes entre chaque module, cette architecture établit une base théorique systématique pour comprendre la logique d'optimisation de l'évolutivité horizontale et de la localité des données des systèmes distribués.
Recommandations connexes
Autres œuvres de l'auteur
Plan/Contenu
Voir plus
Sqoop (assurer la synchronisation des données entre la base de données relationnelle et le HDFS)
HDFS (Système de fichiers distribué)
HBase (base de données distribuée)
Flume (acquisition de journaux)
Hive (entrepôt de données)
Pig (traitement de flux de données)
YARN (Gestion des ressources)
Zookeeper (collaboration distribuée)
Mapreduce (cadre de traitement distribué)
Mahout (bibliothèque d'exploration de données)
Collecter
Collecter
Collecter

Collecter


0 Commentaires
Page suivante