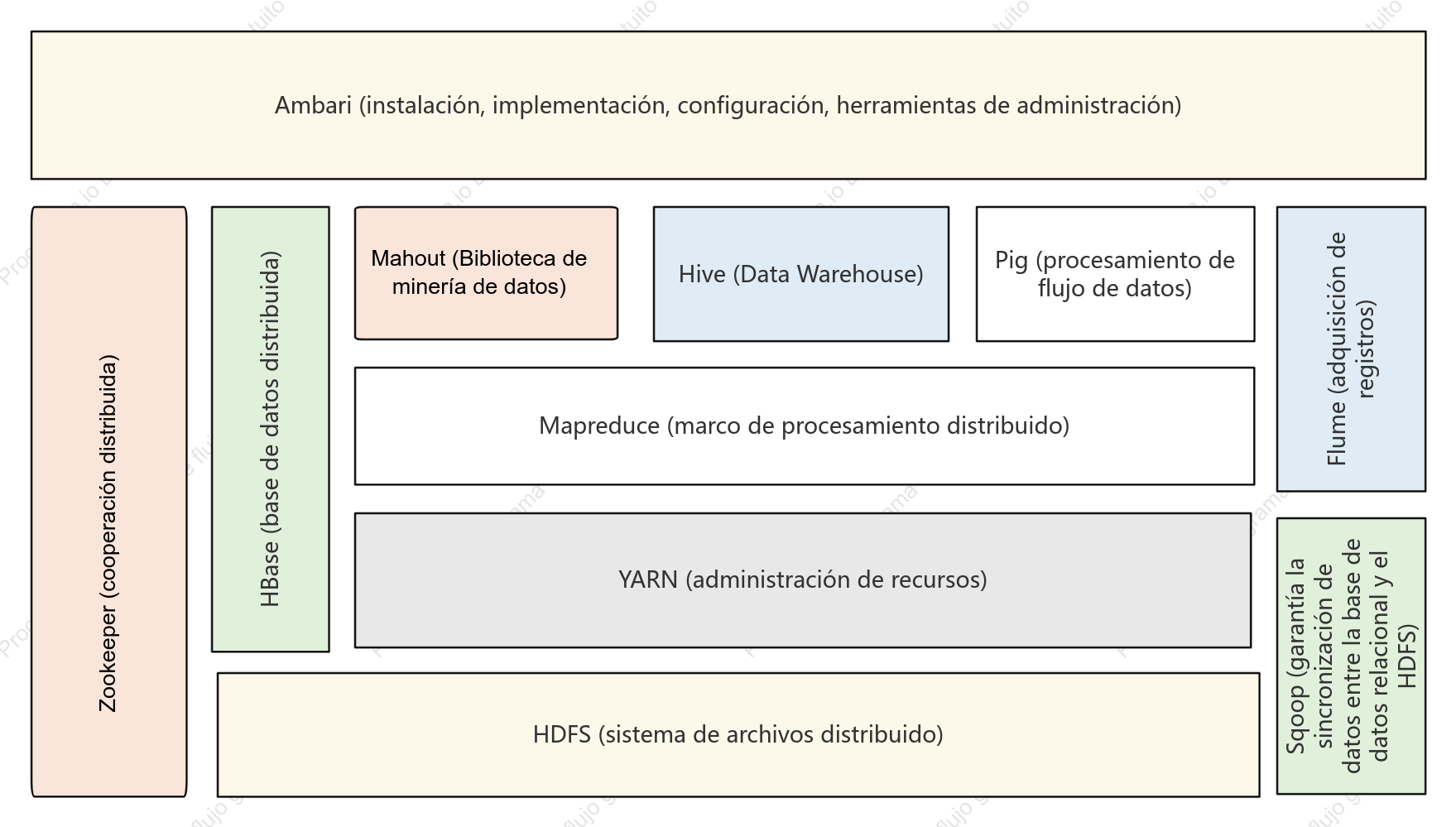

Arquitectura del sistema Hadoop
0 Informe
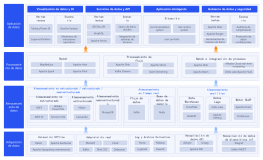
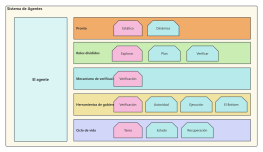
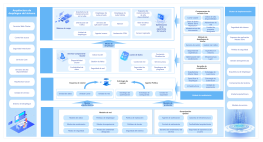
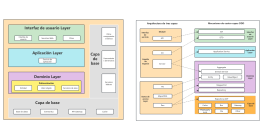
La arquitectura del sistema Hadoop es un diseño fundamental en el campo del procesamiento de big data, cuyo objetivo es lograr un procesamiento altamente confiable y tolerante a fallos de grandes cantidades de datos en clústeres de hardware de propósito general mediante un marco de almacenamiento y computación distribuidos. Esta sección describe sistemáticamente la estructura central en capas de Hadoop, que incluye tres componentes principales: el sistema de archivos distribuidos HDFS, el planificador de recursos YARN y el modelo de computación distribuida MapReduce. HDFS adopta una arquitectura maestro-esclavo, donde el NameNode gestiona los metadatos y los espacios de nombres, y los DataNodes se encargan de almacenar los bloques de datos reales y garantizar la redundancia para asegurar una alta disponibilidad de los datos. YARN, como plataforma de gestión de recursos y planificación de tareas, comprende ResourceManager, NodeManager y ApplicationMaster, desacoplando los recursos de computación de los ciclos de vida de los trabajos. MapReduce define un paradigma de computación paralela para la fragmentación de datos, la ordenación aleatoria (Shuffle) y la agregación reducida (Reduce). Mediante el análisis de los protocolos de interacción, los mecanismos de latido y las estrategias de recuperación de fallos entre cada módulo, esta arquitectura sienta una base teórica sistemática para comprender la lógica de optimización de la escalabilidad horizontal y la localidad de datos de los sistemas distribuidos.
Recomendaciones relacionadas
Otras obras del autor
Esquema/Contenido
Ver más
Sqoop (garantía la sincronización de datos entre la base de datos relacional y el HDFS)
HDFS (sistema de archivos distribuido)
HBase (base de datos distribuida)
Flume (adquisición de registros)
Hive (Data Warehouse)
Pig (procesamiento de flujo de datos)
YARN (administración de recursos)
Zookeeper (cooperación distribuida)
Mapreduce (marco de procesamiento distribuido)
Mahout (Biblioteca de minería de datos)
Recolectar
Recolectar
Recolectar

Recolectar
Collect
Collect

0 Comentarios
Página siguiente