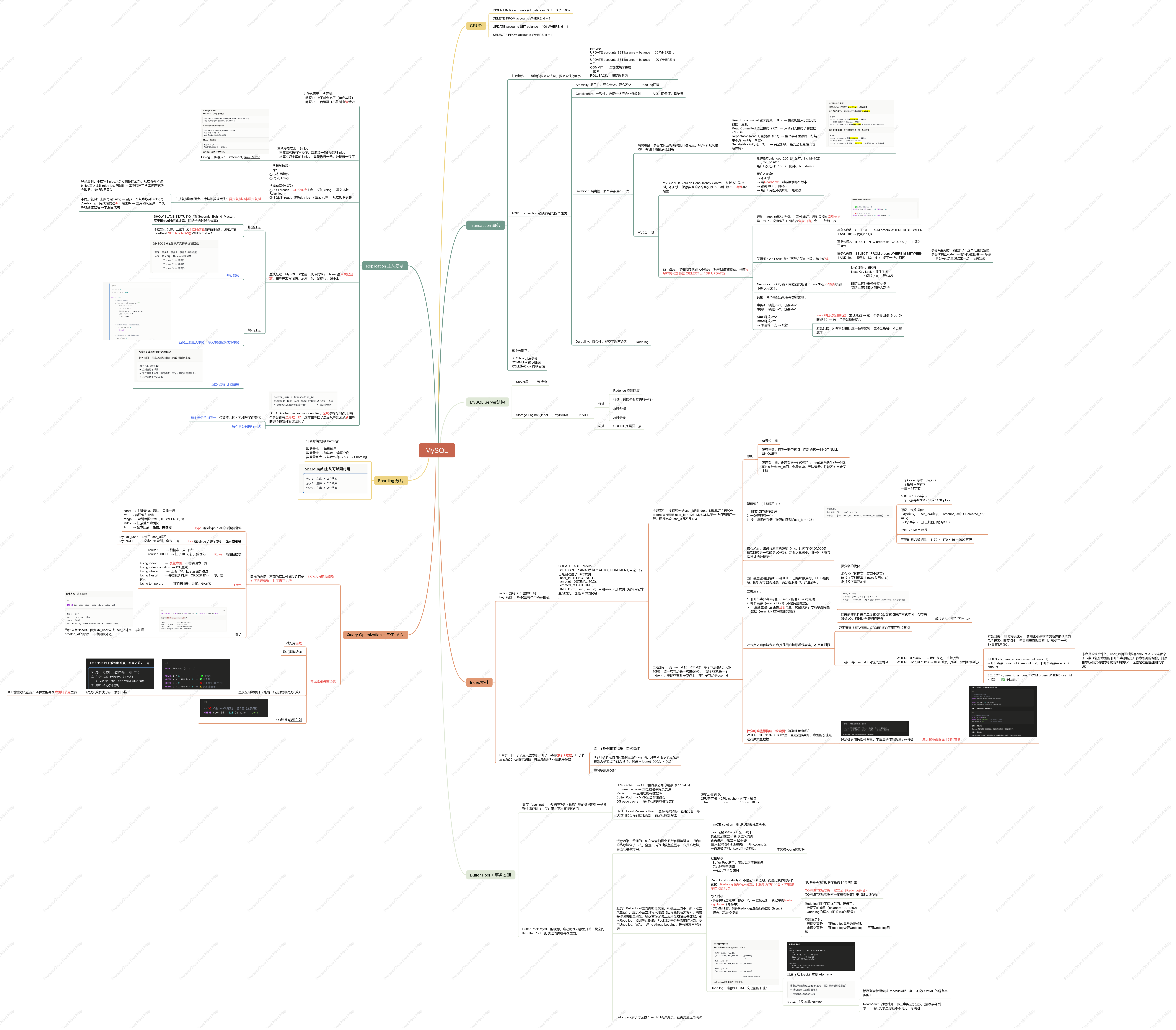

MySQL + InnoDB
0 檢舉
SDE Interview
相關推薦
作者其他創作
大綱/內容
看更多
CRUD
INSERT INTO accounts (id, balance) VALUES (1, 500);
DELETE FROM accounts WHERE id = 1;
UPDATE accounts SET balance = 400 WHERE id = 1;
SELECT * FROM accounts WHERE id = 1;
Transaction 事务
打包操作,一组操作要么全成功,要么全失败回滚
打包操作,一组操作要么全成功,要么全失败回滚
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
COMMIT; -- 全部成功才提交
-- 或者
ROLLBACK; -- 出错就撤销
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
COMMIT; -- 全部成功才提交
-- 或者
ROLLBACK; -- 出错就撤销
ACID: Transaction 必须满足的四个性质
Atomicity: 原子性,要么全做,要么不做
Undo log回滚
Consistency:一致性,数据始终符合业务规则
由AID共同保证,是结果
Isolation:隔离性,多个事务互不干扰
隔离级别:事务之间互相隔离到什么程度,MySQL默认是RR,有四个级别从低到高
Read Uncommitted 读未提交(RU)→ 能读到别人没提交的数据,最乱
Read Committed 读已提交(RC)→ 只读别人提交了的数据 - MVCC
Repeatable Read 可重复读(RR)→ 整个事务里读同一行结果不变 ← MySQL默认
Serializable 串行化(S) → 完全加锁,最安全但最慢(写写冲突)
Read Committed 读已提交(RC)→ 只读别人提交了的数据 - MVCC
Repeatable Read 可重复读(RR)→ 整个事务里读同一行结果不变 ← MySQL默认
Serializable 串行化(S) → 完全加锁,最安全但最慢(写写冲突)
MVCC + 锁
MVCC: Multi-Version Concurrency Control,多版本并发控制,不加锁,保存数据的多个历史版本,读旧版本,读写互不阻塞
用户B改balance:200(新版本,trx_id=102)
↓ roll_pointer
用户B改之前:100(旧版本,trx_id=99)
用户A来读:
→ 不加锁
→ 看ReadView,判断该读哪个版本
→ 读到100(旧版本)
→ 用户B完全不受影响,继续改
↓ roll_pointer
用户B改之前:100(旧版本,trx_id=99)
用户A来读:
→ 不加锁
→ 看ReadView,判断该读哪个版本
→ 读到100(旧版本)
→ 用户B完全不受影响,继续改
锁:占用。你用的时候别人不能用,简单但是性能差,解决写写冲突和加锁读 (SELECT ... FOR UPDATE)
行锁:InnoDB默认行锁,并发性能好,行锁只锁在索引节点这一行上,没有索引时锁进行全表扫描,会扫一行锁一行
间隔锁 Gap Lock:锁住两行之间的空隙,防止幻读
事务A查询:SELECT * FROM orders WHERE id BETWEEN 1 AND 10; → 找到id=1,3,5
事务B插入:INSERT INTO orders (id) VALUES (4); → 插入了id=4
事务A再查:SELECT * FROM orders WHERE id BETWEEN 1 AND 10; → 找到id=1,3,4,5 ← 多了一行,幻读!
事务B插入:INSERT INTO orders (id) VALUES (4); → 插入了id=4
事务A再查:SELECT * FROM orders WHERE id BETWEEN 1 AND 10; → 找到id=1,3,4,5 ← 多了一行,幻读!
事务A查询时,锁住(1,10)这个范围的空隙
事务B想插入id=4 → 被间隙锁阻塞 → 等待
→ 事务A两次查询结果一致,没有幻读
事务B想插入id=4 → 被间隙锁阻塞 → 等待
→ 事务A两次查询结果一致,没有幻读
Next-Key Lock:行锁 + 间隙锁的组合,InnoDB在RR隔离级别下默认用这个。
比如锁住id=5这行:
Next-Key Lock = 锁住(3,5]
= 间隙(3,5) + 行5本身
既防止其他事务修改id=5
又防止在3到5之间插入新行
Next-Key Lock = 锁住(3,5]
= 间隙(3,5) + 行5本身
既防止其他事务修改id=5
又防止在3到5之间插入新行
死锁:两个事务互相等对方释放锁:
事务A:锁住id=1,想要id=2
事务B:锁住id=2,想要id=1
A等B释放id=2
B等A释放id=1
→ 永远等下去 → 死锁
事务A:锁住id=1,想要id=2
事务B:锁住id=2,想要id=1
A等B释放id=2
B等A释放id=1
→ 永远等下去 → 死锁
InnoDB自动检测死锁:发现死锁 → 选一个事务回滚(代价小的那个)→ 另一个事务继续执行
避免死锁:所有事务按照统一顺序加锁,拿不到就等,不会形成环
Durability:持久性,提交了就不会丢
Redo log
三个关键字:
BEGIN = 开启事务
COMMIT = 确认提交
ROLLBACK = 撤销回滚
BEGIN = 开启事务
COMMIT = 确认提交
ROLLBACK = 撤销回滚
MySQL Server结构
Server层
连接池
Storage Engine(InnoDB、MyISAM)
InnoDB
好处
Redo log 崩溃回复
行锁(只锁你要改的那一行)
支持外键
支持事务
坏处
COUNT(*) 需要扫描
Index索引
index(索引):整棵B+树
key(键):B+树里每个节点存的值
key(键):B+树里每个节点存的值
CREATE TABLE orders (
id BIGINT PRIMARY KEY AUTO_INCREMENT, -- 这一行已经自动建了B+树索引
user_id INT NOT NULL,
amount DECIMAL(10,2),
created_at DATETIME,
INDEX idx_user (user_id) -- 给user_id加索引(经常用它来查询的列,也是B+树的树名)
);
id BIGINT PRIMARY KEY AUTO_INCREMENT, -- 这一行已经自动建了B+树索引
user_id INT NOT NULL,
amount DECIMAL(10,2),
created_at DATETIME,
INDEX idx_user (user_id) -- 给user_id加索引(经常用它来查询的列,也是B+树的树名)
);
主键索引:没有额外给user_id加index,SELECT * FROM orders WHERE user_id = 123; MySQL从第一行扫到最后一行,逐行比较user_id是不是123
原则
有显式主键
没有主键,有唯一非空索引:自动选第一个NOT NULL UNIQUE列
既没有主键,也没有唯一非空索引:InnoDB自动生成一个隐藏的6字节row_id列,全局递增,无法查看,性能不如自定义主键
聚簇索引(主键索引):
1. 叶节点存整行数据
2. 一张表只有一个
3. 按主键顺序存储(按照id顺序找use_id = 123)
1. 叶节点存整行数据
2. 一张表只有一个
3. 按主键顺序存储(按照id顺序找use_id = 123)
一个key = 8字节(bigint)
一个指针 = 6字节
一组 = 14字节
16KB = 16384字节
一个节点存16384 / 14 ≈ 1170个key
一个指针 = 6字节
一组 = 14字节
16KB = 16384字节
一个节点存16384 / 14 ≈ 1170个key
假设一行数据有:
id(8字节) + user_id(4字节) + amount(8字节) + created_at(8字节)
= 约28字节,加上其他开销约1KB
16KB / 1KB ≈ 16行
id(8字节) + user_id(4字节) + amount(8字节) + created_at(8字节)
= 约28字节,加上其他开销约1KB
16KB / 1KB ≈ 16行
三层B+树总数据量 = 1170 × 1170 × 16 ≈ 2000万行
核心矛盾:磁盘寻道查找速度10ms,比内存慢100,000倍,每次跳转是一次磁盘I/O次数,需要尽量减少。 B+树: 为磁盘IO设计的数据结构
为什么主键用自增ID不用UUID:自增ID顺序写,UUID随机写,随机写导致页分裂,页分裂浪费IO、产生碎片。
页分裂的代价:
多余IO(读旧页,写两个新页)
碎片(页利用率从100%跌到50%)
高并发下需要加锁
二级索引: 给user_id 加一个B+树,每个节点是1页大小16KB,读一次节点是一次磁盘I/O,(整个树就是一个Index),主键存在叶子节点上,非叶子节点是user_id
二级索引:
1. 非叶节点只存key值(user_id的值) -> 树更矮
2. 叶节点存(user_id + id),不是完整数据行
1. 非叶节点只存key值(user_id的值) -> 树更矮
2. 叶节点存(user_id + id),不是完整数据行
- 3. 查到主键id后还要回表再查一次聚簇索引才能拿到完整数据(user_id=123对应的数据)
回表的随机性来自二级索引和聚簇索引排序方式不同,会带来随机I/O,有时比全表扫描还慢
解决方法:索引下推 ICP
叶节点之间有链表-> 查找范围直接顺着链表走,不用回到根
范围查询(BETWEEN, ORDER BY)不用回到根节点
叶节点:存 user_id + 对应的主键id
WHERE id = 456 -- 用B+树①,直接找到
WHERE user_id = 123 -- 用B+树②,找到主键后回表到①
WHERE user_id = 123 -- 用B+树②,找到主键后回表到①
避免回表: 建立复合索引,覆盖索引是指查询所需的列全部包含在索引叶节点中,无需回表查聚簇索引,减少了一次B+树查找和IO。
INDEX idx_user_amount (user_id, amount)
-- 叶节点存:user_id + amount + id,非叶节点存user_id + amount
-- 叶节点存:user_id + amount + id,非叶节点存user_id + amount
排序是按组合来的,user_id相同时要靠amount来决定走哪个子节点(复合索引的非叶节点存的是所有索引列的组合,排序和导航都按照建索引时的列顺序来。这也是左前缀原则的根源)
SELECT id, user_id, amount FROM orders WHERE user_id = 123; -- ✅ 不回表了
什么时候值得构建二级索引:这列经常出现在WHERE/JOIN/ORDER BY里,且过滤效果好。索引的价值是过滤掉大量数据
过滤效果用选择性衡量:不重复的值的数量 / 总行数
怎么解决低选择性列的查询
B+树:非叶子节点只放索引,叶子节点放索引+数据,叶子节点包括父节点的索引值,并且是按照key值顺序存放
读一个B+树的节点是一次I/O操作
N个叶子节点的时间复杂度为O(logdN),其中 d 表示节点允许的最大子节点个数为 d 个。树高 = log₁₁₇₀(1000万) ≈ 3层
空间复杂度O(N)
Buffer Pool + 事务实现
缓存(caching) = 把慢速存储(磁盘)里的数据复制一份放到快速存储(内存)里,下次直接读内存。
CPU cache → CPU和内存之间的缓存(L1/L2/L3)
Browser cache → 浏览器缓存网页资源
Redis → 应用层缓存数据库
Buffer Pool → MySQL缓存磁盘页
OS page cache → 操作系统缓存磁盘文件
Browser cache → 浏览器缓存网页资源
Redis → 应用层缓存数据库
Buffer Pool → MySQL缓存磁盘页
OS page cache → 操作系统缓存磁盘文件
速度从快到慢:
CPU寄存器 > CPU cache > 内存 > 磁盘
1ns 5ns 100ns 10ms
CPU寄存器 > CPU cache > 内存 > 磁盘
1ns 5ns 100ns 10ms
LRU:Least Recently Used,缓存淘汰策略,链表实现,每次访问的页移到链表头部,满了从尾部淘汰
Buffer Pool: MySQL的缓存,启动时在内存里开辟一块空间,叫Buffer Pool,把读过的页缓存在里面。
缓存污染:普通的LRU在全表扫描会把所有页读进来,把真正的热数据全挤出去,全表扫描的时候有的页不一定是热数据,会造成缓存污染。
InnoDB solution:把LRU链表分成两段:
[ young区 (5/8) | old区 (3/8) ]
真正的热数据 新读进来的页
新页进来:先放old区头部
在old区待够1秒还被访问:升入young区
一直没被访问:从old区尾部淘汰
[ young区 (5/8) | old区 (3/8) ]
真正的热数据 新读进来的页
新页进来:先放old区头部
在old区待够1秒还被访问:升入young区
一直没被访问:从old区尾部淘汰
不污染young区数据
脏页:Buffer Pool里的页被修改后,和磁盘上的不一致(磁盘未更新)。脏页不会立刻写入磁盘(因为随机写太慢),需要等待时机批量刷盘。刷盘前为了防止没刷盘崩溃丢失数据,引入Redo log;如果想让Buffer Pool回到事务开始前的状态,要用Undo log。WAL = Write-Ahead Logging,先写日志再写数据
批量刷盘:
- Buffer Pool满了,淘汰页之前先刷盘
- 后台线程定期刷
- MySQL正常关闭时
- Buffer Pool满了,淘汰页之前先刷盘
- 后台线程定期刷
- MySQL正常关闭时
Redo log (Durability):不是记SQL语句,而是记具体的字节变化,Redo log 顺序写入磁盘,比随机写快100倍(OS的顺序IO和随机IO)
写入时机:
- 事务执行过程中:修改一行 → 立刻追加一条记录到Redo log Buffer(内存中)
- COMMIT时:确保Redo log已经刷到磁盘(fsync)
- 脏页:之后慢慢刷
写入时机:
- 事务执行过程中:修改一行 → 立刻追加一条记录到Redo log Buffer(内存中)
- COMMIT时:确保Redo log已经刷到磁盘(fsync)
- 脏页:之后慢慢刷
"数据安全"和"数据在磁盘上"是两件事:
COMMIT之后数据一定安全(Redo log保证)
COMMIT之后数据不一定在数据文件里(脏页还没刷)
COMMIT之后数据一定安全(Redo log保证)
COMMIT之后数据不一定在数据文件里(脏页还没刷)
Redo log保护了两样东西,记录了:
- 数据页的修改(balance: 100→200)
- Undo log的写入(旧值100的记录)
崩溃重启时:
- 已提交事务 → 用Redo log重放数据修改
- 未提交事务 → 用Redo log恢复Undo log → 再用Undo log回滚
- 数据页的修改(balance: 100→200)
- Undo log的写入(旧值100的记录)
崩溃重启时:
- 已提交事务 → 用Redo log重放数据修改
- 未提交事务 → 用Redo log恢复Undo log → 再用Undo log回滚
Undo log:储存“UPDATE改之前的旧值”
回滚(Rollback)实现 Atomicity
MVCC 并发 实现Isolation
活跃列表就是创建ReadView那一刻,还没COMMIT的所有事务的ID
ReadView:创建时刻,哪些事务还没提交(活跃事务列表),活跃列表里的版本不可见,可跳过
buffer pool满了怎么办?→ LRU淘汰冷页,脏页先刷盘再淘汰
Replication 主从复制
为什么需要主从复制:
- 问题1:挂了就全完了(单点故障)
- 问题2:一台机器扛不住所有读请求
- 问题1:挂了就全完了(单点故障)
- 问题2:一台机器扛不住所有读请求
主从复制实现:Binlog
- 主库每次执行写操作,都追加一条记录到Binlog
- 从库拉取主库的Binlog,重新执行一遍,数据就一致了
- 主库每次执行写操作,都追加一条记录到Binlog
- 从库拉取主库的Binlog,重新执行一遍,数据就一致了
Binlog 三种格式: Statement, Row, Mixed
主从复制流程:
主库:
① 执行写操作
② 写入Binlog
从库有两个线程:
① IO Thread:TCP长连接主库,拉取Binlog → 写入本地Relay log
② SQL Thread:读Relay log → 重放执行 → 从库数据更新
主库:
① 执行写操作
② 写入Binlog
从库有两个线程:
① IO Thread:TCP长连接主库,拉取Binlog → 写入本地Relay log
② SQL Thread:读Relay log → 重放执行 → 从库数据更新
主从复制如何避免主库挂掉数据丢失:异步复制vs半同步复制
异步复制:主库写Binlog之后立刻返回成功,从库慢慢拉取binlog写入本地relay log, 风险时主库突然挂了从库还没更新完数据,造成数据丢失
半同步复制:主库写完binlog → 至少一个从库收到Binlog写入relay log,完成后发送ACK给主库 → 主库确认至少一个从库收到数据后 →才返回成功
主从延迟:MySQL 5.6之前,从库的SQL Thread是单线程回放,主库并发写很快,从库一条一条执行,追不上
排查延迟
SHOW SLAVE STATUS\G(看 Seconds_Behind_Master,基于Binlog时间戳计算,网络卡的时候会失真)
主库写心跳表,从库对比主库时间戳和当前时间:UPDATE heartbeat SET ts = NOW() WHERE id = 1;
解决延迟
并行复制
业务上避免大事务,将大事务拆解成小事务
读写分离时处理延迟
GTID:Global Transaction Identifier,全局事物标识符, 即每个事务都有全局唯一ID,这样主库挂了之后从库知道从新主库的哪个位置开始继续同步
每个事务全局唯一,位置不会因为机器坏了而变化
每个事务只执行一次
Sharding 分片
什么时候需要Sharding:
数据量小 → 单机够用
数据量大 → 加从库,读写分离
数据量巨大 → 从库也存不下了 → Sharding
数据量小 → 单机够用
数据量大 → 加从库,读写分离
数据量巨大 → 从库也存不下了 → Sharding
Query Optimization + EXPLAIN
同样的数据,不同的写法性能差几百倍,EXPLAIN用来解释如何执行查询,并不真正执行
Type, 看到type = all的时候要警惕
const → 主键查询,最快,只找一行
ref → 普通索引查询
range → 索引范围查询(BETWEEN, >, <)
index → 扫描整个索引树
ALL → 全表扫描,最慢,要优化
ref → 普通索引查询
range → 索引范围查询(BETWEEN, >, <)
index → 扫描整个索引树
ALL → 全表扫描,最慢,要优化
Key 看实际用了哪个索引,显示索引名
key: idx_user → 走了user_id索引
key: NULL → 没走任何索引,全表扫描
key: NULL → 没走任何索引,全表扫描
Rows:预估扫描数
rows: 1 → 很精准,只扫1行
rows: 1000000 → 扫了100万行,要优化
rows: 1000000 → 扫了100万行,要优化
Extra
Using index → 覆盖索引,不需要回表,好
Using index condition → ICP生效
Using where → 没有ICP,回表后额外过滤
Using filesort → 需要额外排序(ORDER BY),慢,要优化
Using temporary → 用了临时表,更慢,要优化
Using index condition → ICP生效
Using where → 没有ICP,回表后额外过滤
Using filesort → 需要额外排序(ORDER BY),慢,要优化
Using temporary → 用了临时表,更慢,要优化
例子
为什么有filesort?因为idx_user只按user_id排序,不知道created_at的顺序,排序要额外做。
常见索引失效场景
对列用函数
隐式类型转换
违反左前缀原则(最后一行是索引部分失效)
部分失效解决办法:索引下推
ICP能生效的前提:条件里的列在索引叶节点里有
OR连接x非索引列
收藏

0 則評論
下一頁