
Процесс поиска RAG большой языковой модели искусственного интеллекта
0 Oтчет
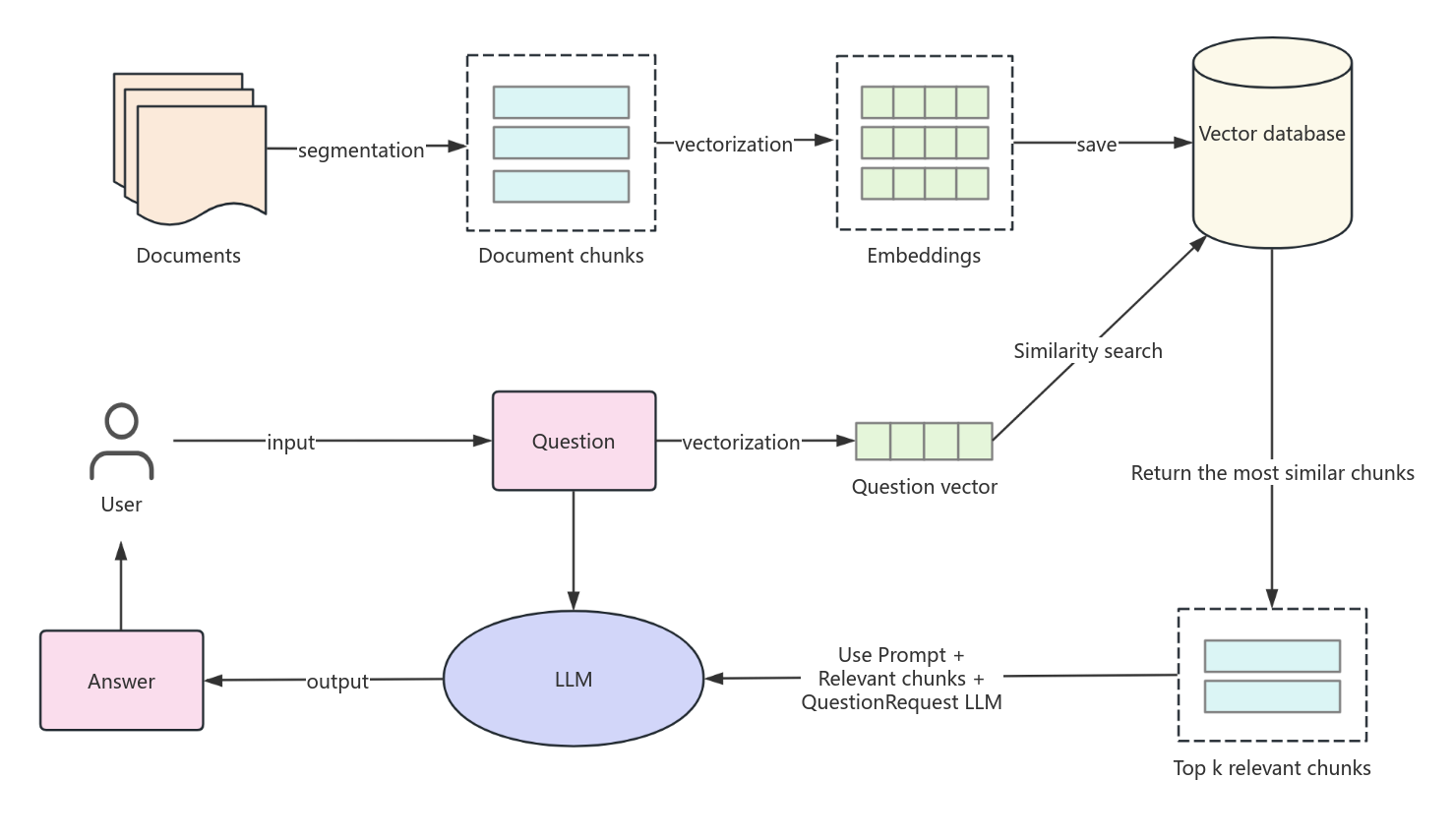
Данная блок-схема описывает процесс поиска информации с использованием большой языковой модели (LLM) и векторной базы данных. Процесс начинается с ввода вопроса пользователем, после чего вопрос подвергается векторизации. Вектор вопроса используется для поиска схожих документов в векторной базе данных. Документы предварительно сегментируются на части, которые также векторизуются для облегчения поиска. На основе результатов поиска выбираются наиболее релевантные фрагменты документов. Эти фрагменты, вместе с исходным вопросом и специальной подсказкой, отправляются в LLM для генерации ответа. В результате пользователь получает ответ, основанный на наиболее подходящих частях документов, найденных в базе данных.
Связанные рекомендации
Другие работы автора
План/Содержание
Смотреть больше
Vector database
Documents
save
output
Use Prompt +Relevant chunks +QuestionRequest LLM
Answer
Similarity search
Question vector
vectorization
input
LLM
Embeddings
User
Document chunks
segmentation
Return the most similar chunks
Question
Top k relevant chunks
Cобирать
Cобирать
Cобирать
Cобирать

0 Комментарии
Следующая страница