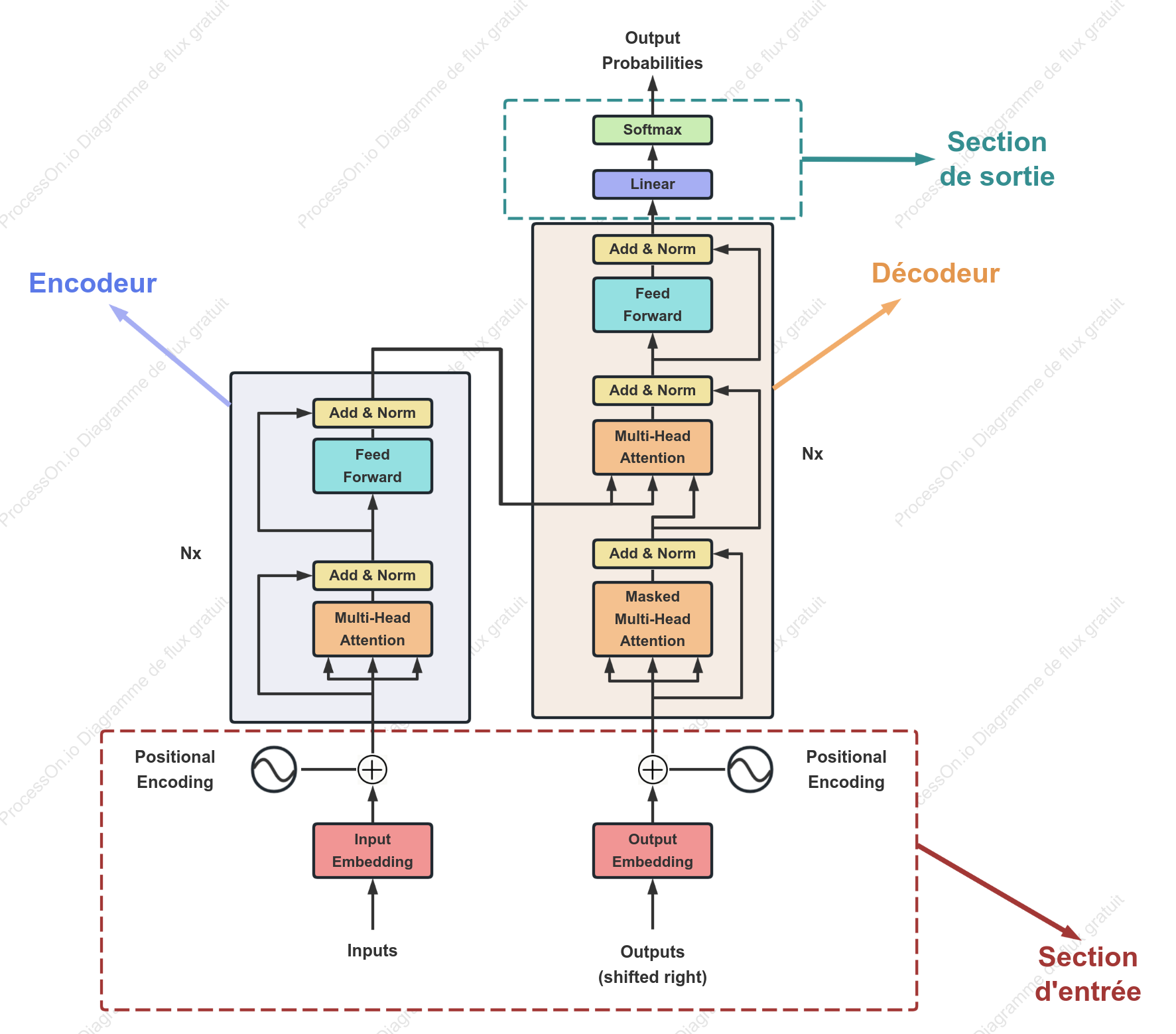

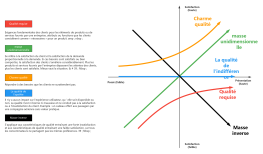
Architecture du modèle Transformer
0 Rapport
Ce modèle est idéal pour dessiner des diagrammes de structure de réseaux neuronaux de type Transformer, en mettant l'accent sur les composants essentiels de l'encodeur et du décodeur ainsi que sur leurs flux de données. Il présente clairement des modules tels que l'intégration des entrées, l'encodage positionnel, l'auto-attention multi-têtes, le réseau à propagation directe, la normalisation des couches et les connexions résiduelles. Il convient parfaitement comme illustration dans des articles, des présentations techniques, des tutoriels explicatifs de modèles ou des documents de reproduction d'algorithmes, permettant ainsi aux lecteurs de comprendre intuitivement le fonctionnement du Transformer et les chemins de transmission des informations.
Recommandations connexes
Autres œuvres de l'auteur
Plan/Contenu
Voir plus
Add & Norm
PositionalEncoding
Section d'entrée
Nx
Linear
FeedForward
Encodeur
Section de sortie
OutputProbabilities
MaskedMulti-HeadAttention
Multi-HeadAttention
OutputEmbedding
Outputs(shifted right)
InputEmbedding
Softmax
Inputs
Décodeur
Collecter
Collecter

Collect


Collect

0 Commentaires
Page suivante