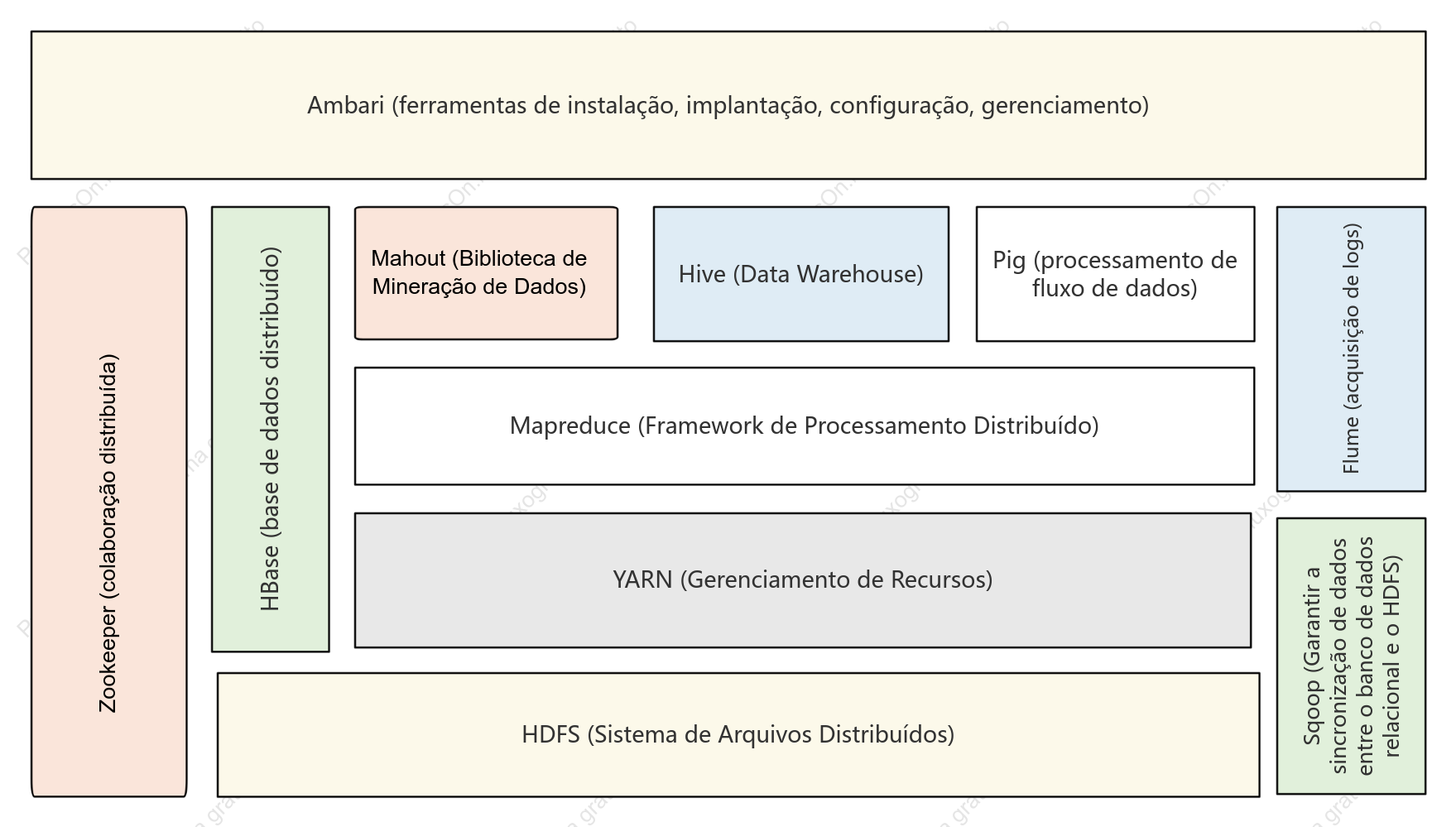

Arquitetura do sistema Hadoop
0 Relatório
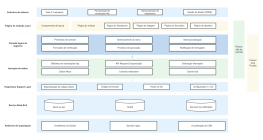
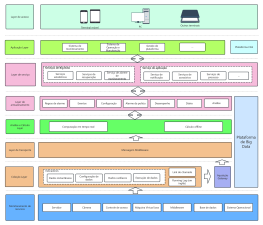
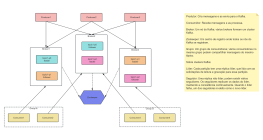
A arquitetura do sistema Hadoop é um projeto fundamental na área de processamento de big data, visando alcançar o processamento altamente confiável e tolerante a falhas de grandes volumes de dados em clusters de hardware de uso geral, por meio de uma estrutura de armazenamento e computação distribuída. Esta seção descreve sistematicamente a estrutura em camadas do Hadoop, incluindo três componentes principais: o sistema de arquivos distribuído HDFS, o agendador de recursos YARN e o modelo de computação distribuída MapReduce. O HDFS adota uma arquitetura mestre-escravo, com o NameNode gerenciando metadados e namespaces, e os DataNodes responsáveis por armazenar os blocos de dados reais e garantir redundância para assegurar alta disponibilidade dos dados. O YARN, como plataforma de gerenciamento de recursos e agendamento de tarefas, engloba o ResourceManager, o NodeManager e o ApplicationMaster, desacoplando os recursos computacionais dos ciclos de vida dos jobs. O MapReduce define um paradigma de computação paralela para fragmentação de dados, ordenação Shuffle e agregação Reduce. Ao analisar os protocolos de interação, os mecanismos de pulsação e as estratégias de recuperação de falhas entre cada módulo, esta arquitetura estabelece uma base teórica sistemática para a compreensão da lógica de otimização da escalabilidade horizontal e da localidade de dados em sistemas distribuídos.
Recomendações relacionadas
Outras obras do autor
Esboço/Conteúdo
Ver mais
Sqoop (Garantir a sincronização de dados entre o banco de dados relacional e o HDFS)
HDFS (Sistema de Arquivos Distribuídos)
HBase (base de dados distribuído)
Flume (acquisição de logs)
Hive (Data Warehouse)
Pig (processamento de fluxo de dados)
YARN (Gerenciamento de Recursos)
Zookeeper (colaboração distribuída)
Mapreduce (Framework de Processamento Distribuído)
Mahout (Biblioteca de Mineração de Dados)



0 Comentários
Próxima página