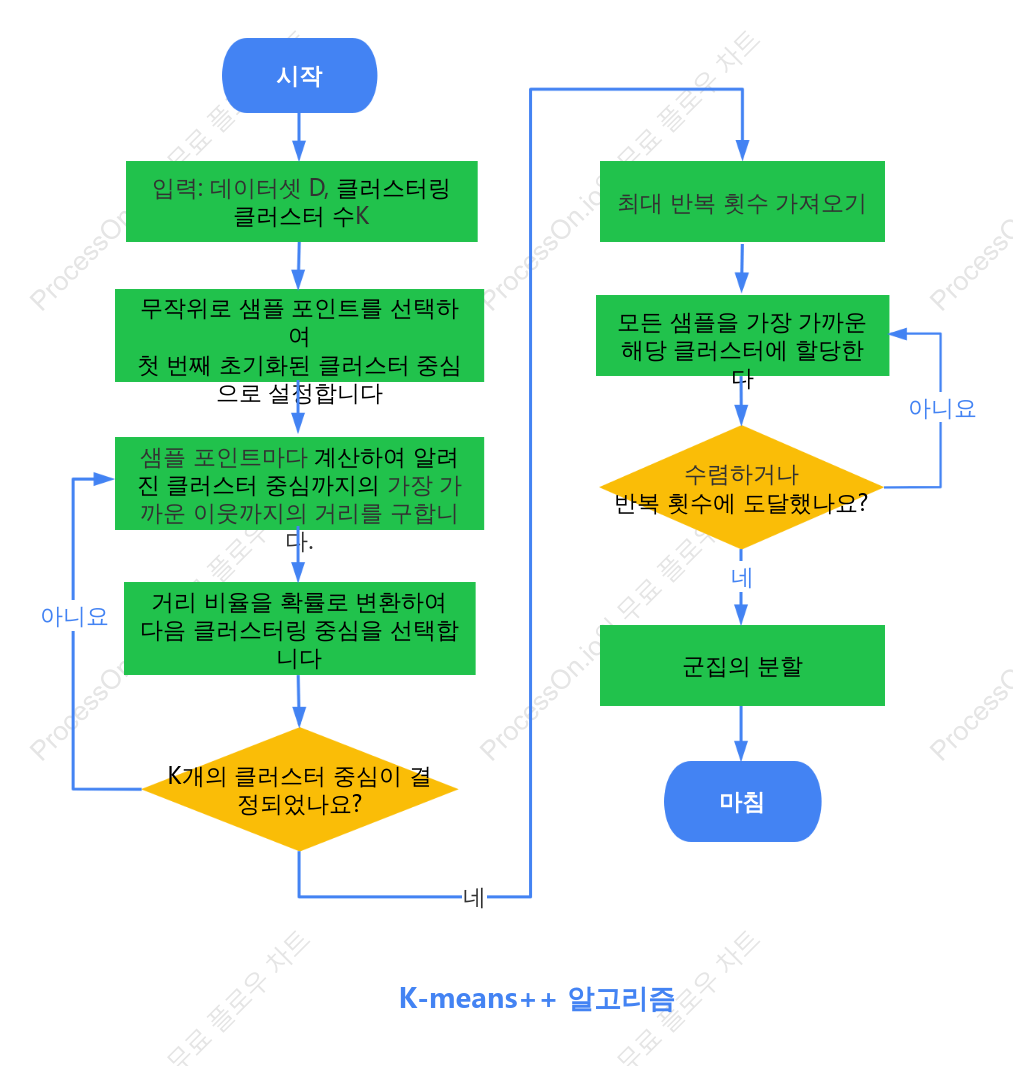

클러스터링 K-means++ 알고리즘 프로세스
0 보고서
클러스터링 K-means++ 알고리즘 프로세스는 데이터 분석에서 효율적인 클러스터링을 위한 방법론을 설명하는 플로차트입니다. 이 알고리즘은 초기 클러스터 중심을 똑똑하게 선택하여 K-means의 성능을 향상시키는 데 중점을 둡니다. 프로세스는 시작 지점에서 최대 반복 횟수를 설정하고, 각 샘플 포인트에 대해 적절한 클러스터를 할당하는 과정을 포함합니다. 알고리즘은 수렴 조건을 만족할 때까지 반복되며, 최종적으로 클러스터링이 완료됩니다. 이 알고리즘은 데이터의 자연스러운 그룹을 찾는 데 유용합니다.
관련 권장 사항
저자의 다른 작품
개요/내용
더 보기
군집의 분할
무작위로 샘플 포인트를 선택하여첫 번째 초기화된 클러스터 중심으로 설정합니다
수렴하거나 반복 횟수에 도달했나요?
아니요
K개의 클러스터 중심이 결정되었나요?
모든 샘플을 가장 가까운 해당 클러스터에 할당한다
시작
네
거리 비율을 확률로 변환하여다음 클러스터링 중심을 선택합니다
마침
최대 반복 횟수 가져오기
K-means++ 알고리즘
샘플 포인트마다 계산하여 알려진 클러스터 중심까지의 가장 가까운 이웃까지의 거리를 구합니다.

즐겨찾기
즐겨찾기
즐겨찾기
즐겨찾기

0 댓글
다음 페이지