
Hadoopシステムアーキテクチャ
0 報告
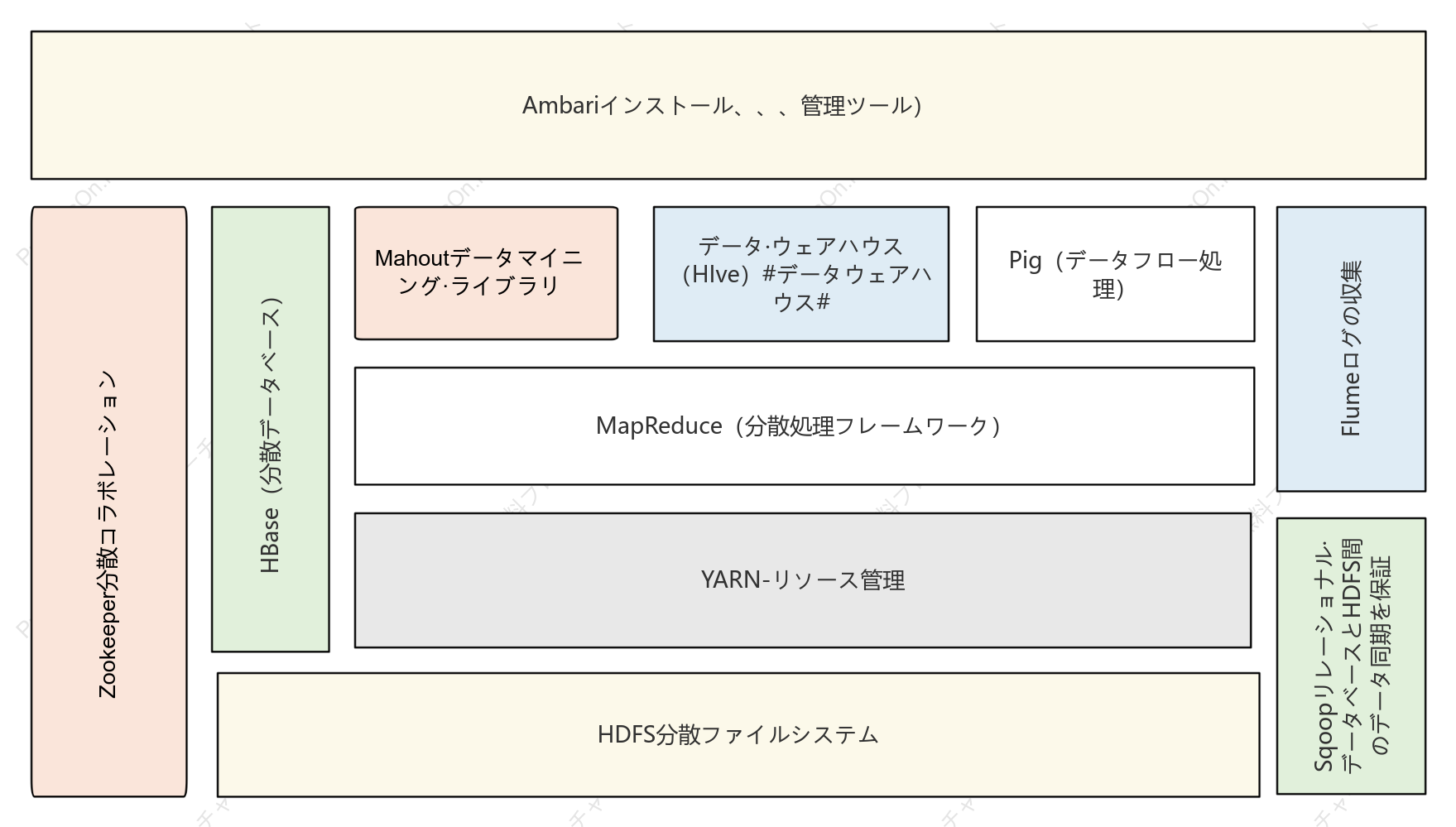
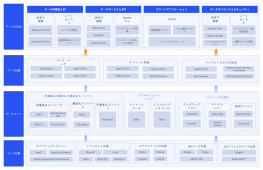
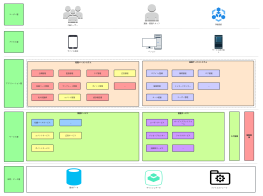
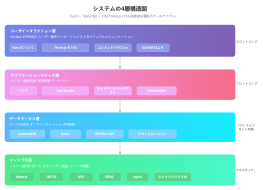
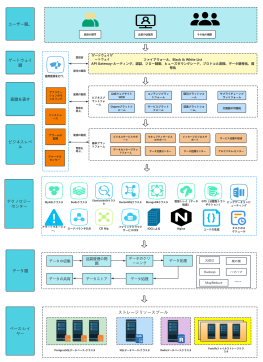
Hadoop システムアーキテクチャは、ビッグデータ処理分野における基盤となる設計であり、分散ストレージおよびコンピューティングフレームワークを通じて、汎用ハードウェアクラスタ上で膨大な量のデータを高信頼性かつ耐障害性で処理することを目指しています。このセクションでは、HDFS 分散ファイルシステム、YARN リソーススケジューラ、MapReduce 分散コンピューティングモデルという 3 つのコアコンポーネントを含む、Hadoop のコア階層構造を体系的に説明します。HDFS はマスタースレーブアーキテクチャを採用しており、NameNode がメタデータと名前空間を管理し、DataNode が実際のデータブロックを格納し、冗長性を確保して高いデータ可用性を保証します。YARN は、リソース管理およびタスクスケジューリングプラットフォームとして、ResourceManager、NodeManager、ApplicationMaster で構成され、コンピューティングリソースをジョブライフサイクルから分離します。MapReduce は、データシャーディング、シャッフルソート、および Reduce 集約のための並列コンピューティングパラダイムを定義します。このアーキテクチャは、各モジュール間の相互作用プロトコル、ハートビートメカニズム、および障害回復戦略を分析することにより、分散システムの水平スケーラビリティとデータ局所性最適化ロジックを理解するための体系的な理論的基盤を構築する。
関連する推奨事項
著者の他の作品
概要/内容
もっと見る
Sqoopリレーショナル·データベースとHDFS間のデータ同期を保証
HDFS分散ファイルシステム
HBase(分散データベース)
Flumeログの収集
データ·ウェアハウス(HIve)#データウェアハウス#
Pig(データフロー処理)
YARN-リソース管理
Zookeeper分散コラボレーション
Ambariインストール、、、管理ツール)
MapReduce(分散処理フレームワーク)
Mahoutデータマイニング·ライブラリ
Collect
Collect
Collect
Collect

0 コメント
次のページ