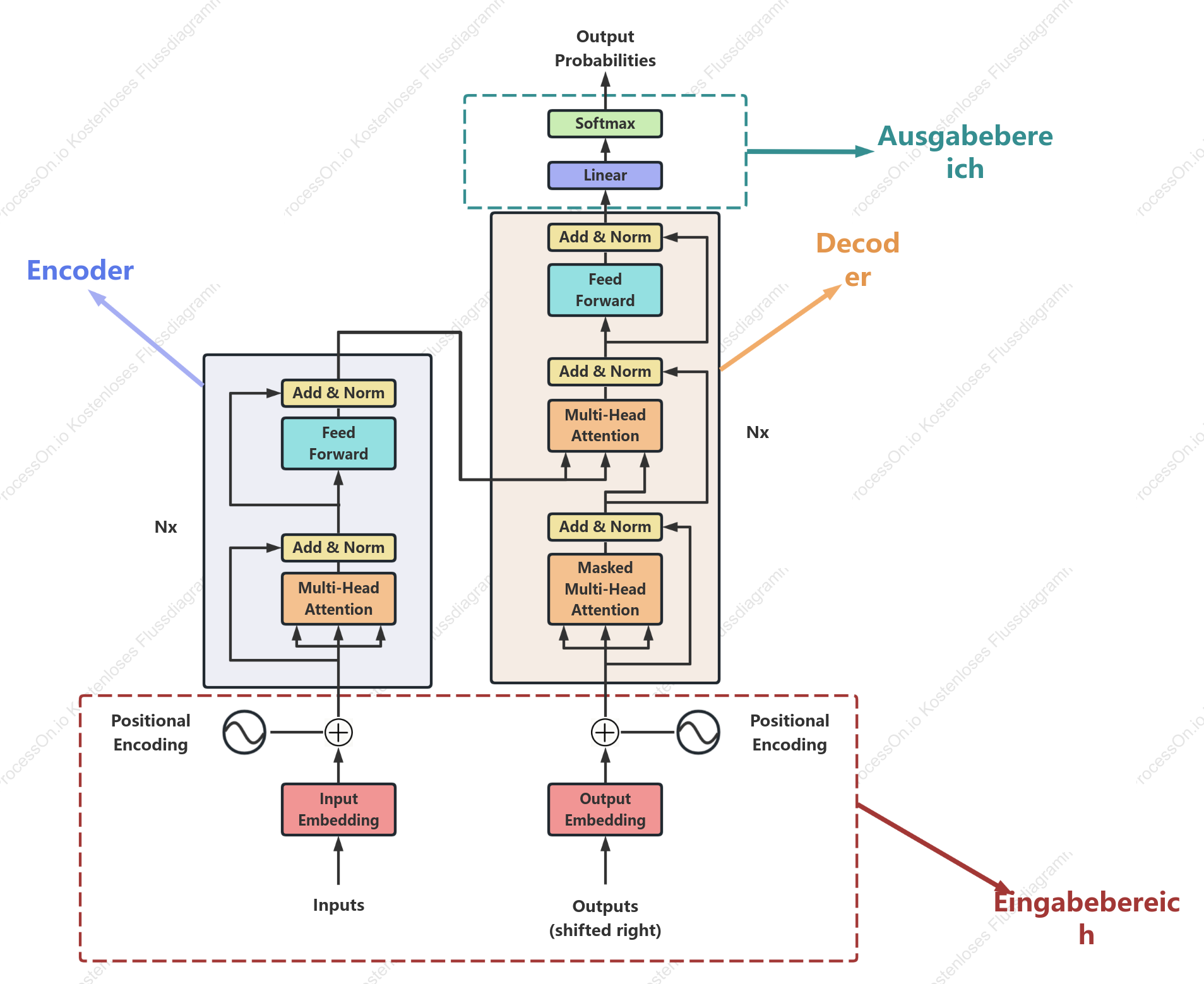

Transformator-Modellarchitektur
0 Bericht
Diese Vorlage eignet sich zur Erstellung von Strukturdiagrammen neuronaler Netze von Transformer-Modellen. Der Fokus liegt dabei auf den Kernkomponenten Encoder und Decoder sowie deren Datenflussbeziehungen. Module wie Input Embedding, Positionskodierung, Multi-Head Self-Attention, Feedforward-Netzwerk, Layer-Normalisierung und Residualverbindungen werden übersichtlich dargestellt. Die Vorlage ist ideal für Illustrationen in wissenschaftlichen Artikeln, Präsentationsfolien, Modellerklärungen oder Algorithmen-Reproduktionsdateien und hilft Lesern, den Workflow und die Informationsübertragungswege des Transformers intuitiv zu verstehen.
Verwandte Empfehlungen
Weitere Werke des Autors
Gliederung/Inhalt
Mehr anzeigen
Add & Norm
PositionalEncoding
Eingabebereich
Nx
Linear
FeedForward
Encoder
Ausgabebereich
OutputProbabilities
MaskedMulti-HeadAttention
Multi-HeadAttention
OutputEmbedding
Outputs(shifted right)
InputEmbedding
Softmax
Inputs
Decoder
Sammeln
Sammeln
Sammeln

0 Kommentare
Nächste Seite