
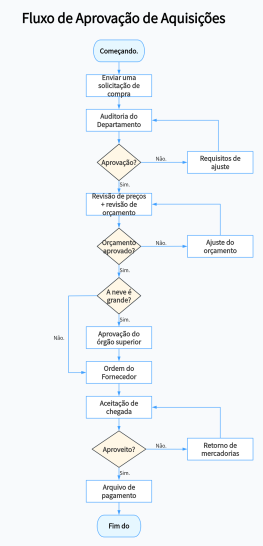
Fluxograma de geração de aprimoramento de recuperação de modelo de linguagem grande AI RAG
0 Relatório
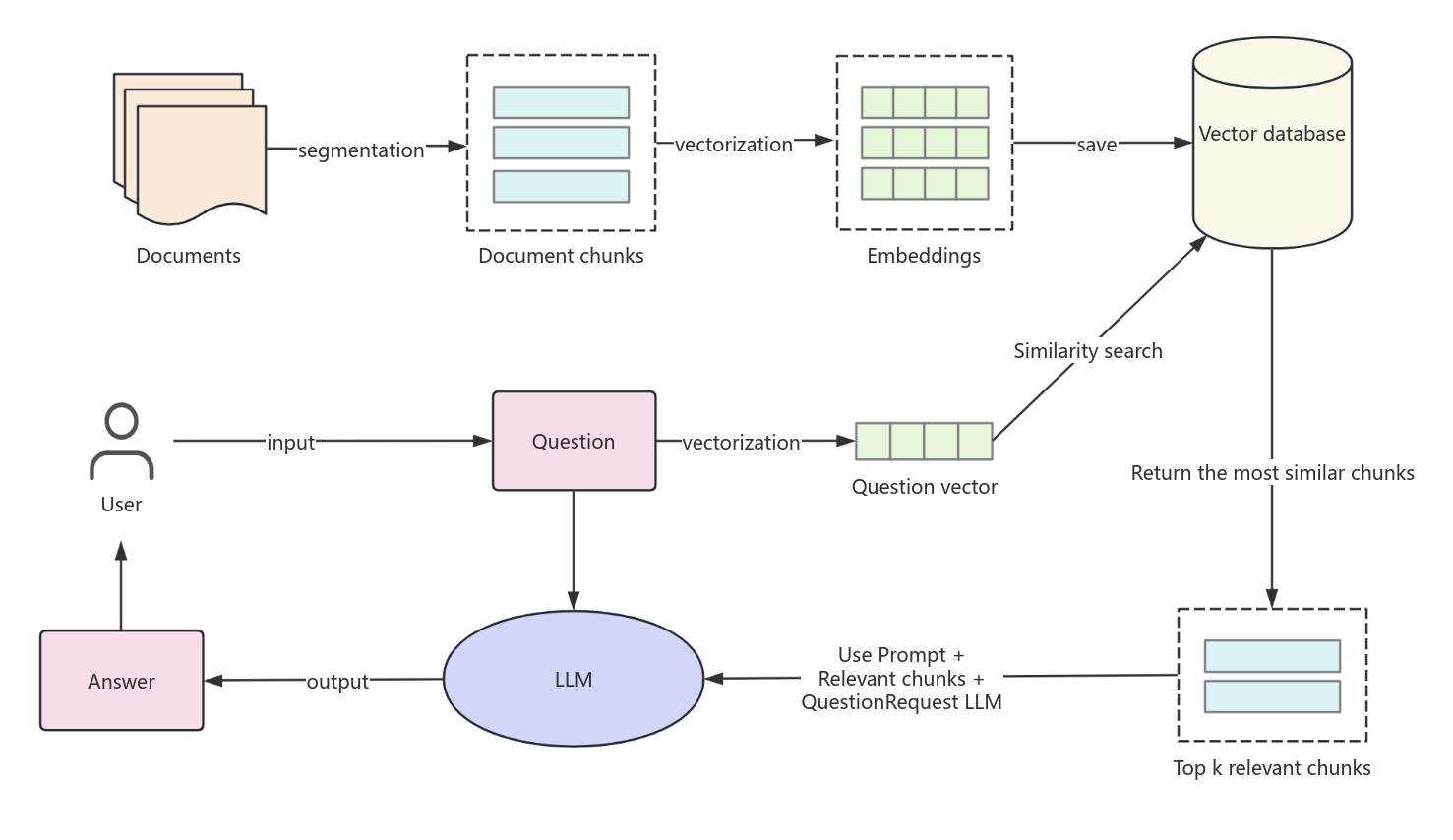
O fluxograma de geração de aprimoramento de recuperação de modelo de linguagem grande AI RAG ilustra o processo de otimização na interação entre usuários e modelos de linguagem. Inicia-se com a segmentação de documentos em pedaços gerenciáveis, que são então vetorizados e armazenados em um banco de dados vetorial. A partir de uma consulta do usuário, uma busca por similaridade é realizada para identificar os pedaços mais relevantes. Esses pedaços, juntamente com a consulta, são utilizados para solicitar respostas do modelo de linguagem, garantindo uma resposta precisa e contextualizada.
Recomendações relacionadas
Outras obras do autor
Esboço/Conteúdo
Ver mais
Vector database
Documents
save
output
Use Prompt +Relevant chunks +QuestionRequest LLM
Answer
Similarity search
Question vector
vectorization
input
LLM
Embeddings
User
Document chunks
segmentation
Return the most similar chunks
Question
Top k relevant chunks



0 Comentários
Próxima página