

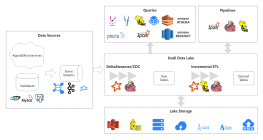
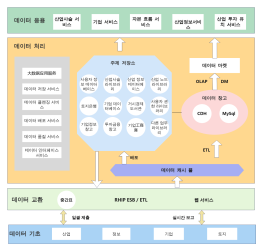
빅 데이터 기술 아키텍처 다이어그램
2 보고서
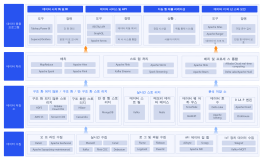
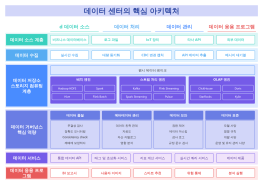
이는 빅 데이터 기술 아키텍처 다이어그램으로, 다양한 데이터 처리 및 분석 기술을 통합하여 실시간 계산, 데이터 저장, 기계 학습, 그리고 지능형 서비스 제공을 지원하는 구조를 설명합니다. 이 아키텍처는 MongoDB, Kafka, Spark Streaming, TensorFlow 등을 활용하여 데이터의 수집, 변환, 저장, 분석을 수행합니다. 또한, 메타데이터 관리 플랫폼, 데이터 품질 플랫폼, 운영 및 유지보수 플랫폼 등을 통해 데이터의 효율적 관리와 운영을 지원합니다. 이를 통해 스마트 서비스, 추천 엔진, 통계 분석 등 다양한 응용 서비스를 제공합니다.
관련 권장 사항
저자의 다른 작품
개요/내용
더 보기
실시간 계산
MongoDB
Sqoop
연구 통계 서비스
메타데이터 관리 플랫폼
OpenCV
기계 학습
스마트 서비스
처리
智能 추천 엔진
텐서플로우
통계 분석 라이브러리
마이크로 서비스 분석
로그 데이터
운영 인력
스톰
카프카
스파크 스트리밍
변환
모델 훈련
엘라스틱서치
문서 데이터
사업 데이터
RDBMS
프로세스 데이터
플루메
개방형 플랫폼
저장 계층
데이터 관리 데이터베이스
RDS
운영 및 유지 관리 플랫폼
씻기
제품
파일
추출
개발 플랫폼
메시지 큐
개방 SDK
개발자
레디스 클러스터
분류
캐시
보스
데이터허브
스파크 SQL
공개 API
중간 계층
케잌
해석
데이터 서비스 계층
작업 스케줄링 플랫폼
데이터 응용 계층
데이터 플랫폼
재무 통계 서비스
HBase
지능적인 스케줄링 엔진
중복 제거
운영 및 유지보수 인력
ElasticSearch 클러스터
AI 지능
HDFS
원데이터
계산 계층
경보 모니터링 플랫폼
운영 및 유지보수 관리
데이터 품질 플랫폼
재무 데이터
산업 데이터
오프라인 계산
Hive/Pig
정부 기업 데이터
사용자 데이터
OSS
마훗
Map/Reduce
선별
사용자 통계 서비스
로그스태시

즐겨찾기
즐겨찾기
즐겨찾기
즐겨찾기
Collect
Collect
Collect
Collect

0 댓글
다음 페이지