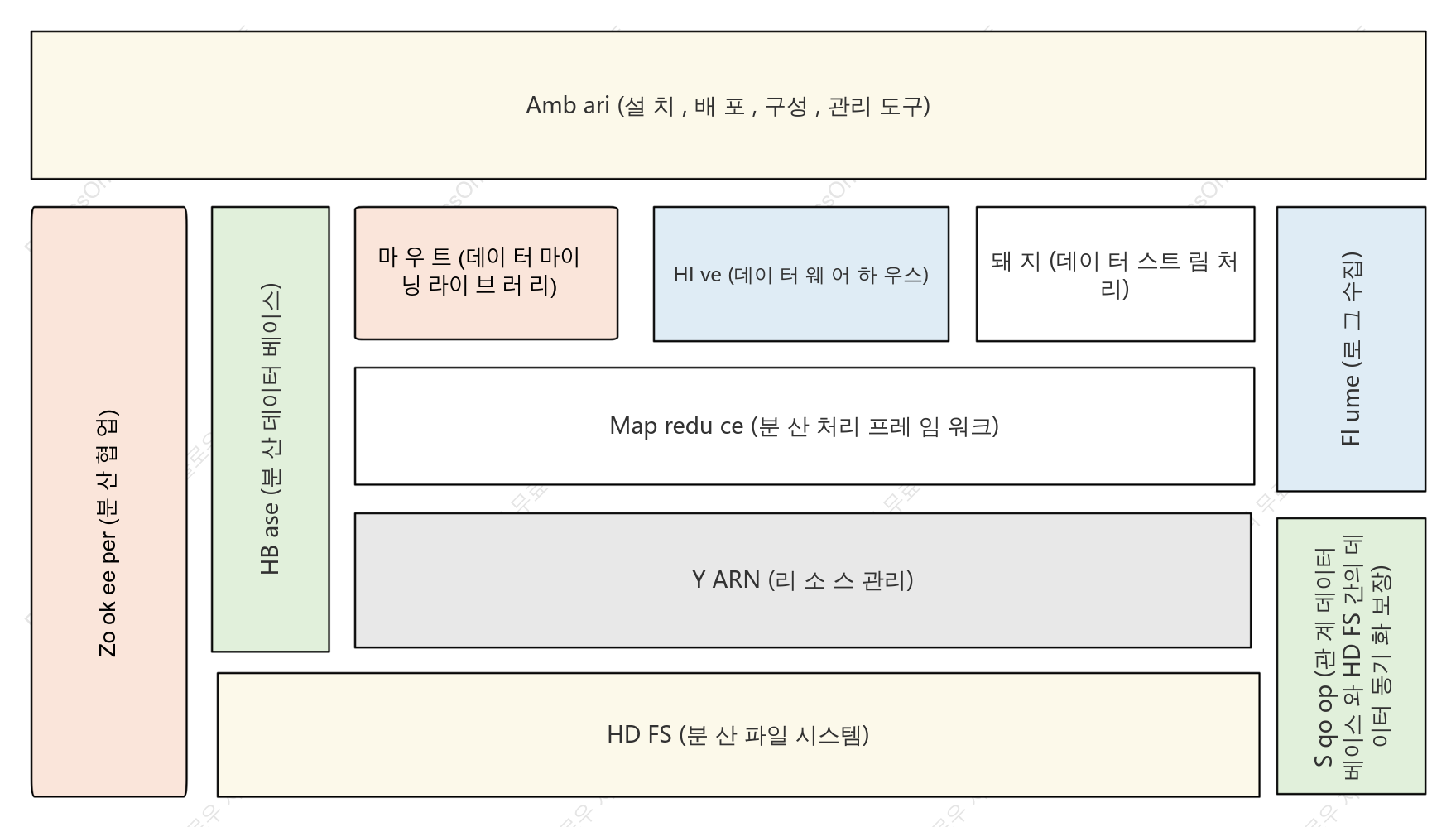

하둡 시스템 아키텍처
0 보고서
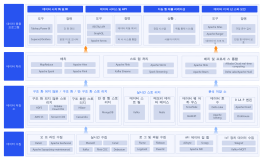
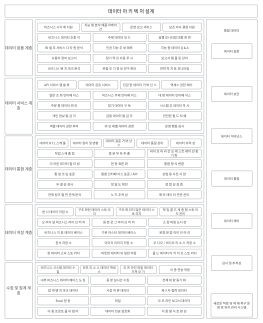
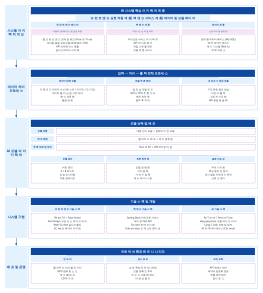
하둡 시스템 아키텍처는 빅데이터 처리 분야의 핵심 설계로서, 분산 스토리지 및 컴퓨팅 프레임워크를 통해 범용 하드웨어 클러스터에서 대규모 데이터의 고신뢰성 및 내결함성 처리를 목표로 합니다. 이 섹션에서는 하둡의 핵심 계층 구조를 체계적으로 설명하며, HDFS 분산 파일 시스템, YARN 리소스 스케줄러, MapReduce 분산 컴퓨팅 모델이라는 세 가지 핵심 구성 요소를 중점적으로 다룹니다. HDFS는 마스터-슬레이브 아키텍처를 채택하여, 네임노드(NameNode)가 메타데이터와 네임스페이스를 관리하고, 데이터노드(DataNode)는 실제 데이터 블록을 저장하고 높은 데이터 가용성을 보장하기 위한 중복성을 담당합니다. YARN은 리소스 관리 및 작업 스케줄링 플랫폼으로서, ResourceManager, NodeManager, ApplicationMaster를 포함하며, 컴퓨팅 리소스를 작업 수명 주기와 분리합니다. MapReduce는 데이터 분할, 셔플 정렬, 리듀스 집계를 위한 병렬 컴퓨팅 패러다임을 정의합니다. 이 아키텍처는 각 모듈 간의 상호 작용 프로토콜, 하트비트 메커니즘 및 오류 복구 전략을 분석함으로써 분산 시스템의 수평적 확장성과 데이터 지역성 최적화 논리를 이해하기 위한 체계적인 이론적 토대를 마련합니다.
관련 권장 사항
저자의 다른 작품
개요/내용
더 보기
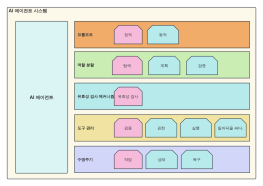
S qo op (관 계 데이터 베이스 와 HD FS 간의 데이터 동기 화 보장)
HD FS (분 산 파일 시스템)
HB ase (분 산 데이터 베이스)
Fl ume (로 그 수집)
HI ve (데이 터 웨 어 하 우스)
돼 지 (데이 터 스트 림 처리)
Y ARN (리 소 스 관리)
Zo ok ee per (분 산 협 업)
Map redu ce (분 산 처리 프레 임 워크)
마 우 트 (데이 터 마이 닝 라이 브 러 리)

Collect
Collect
Collect
Collect

0 댓글
다음 페이지